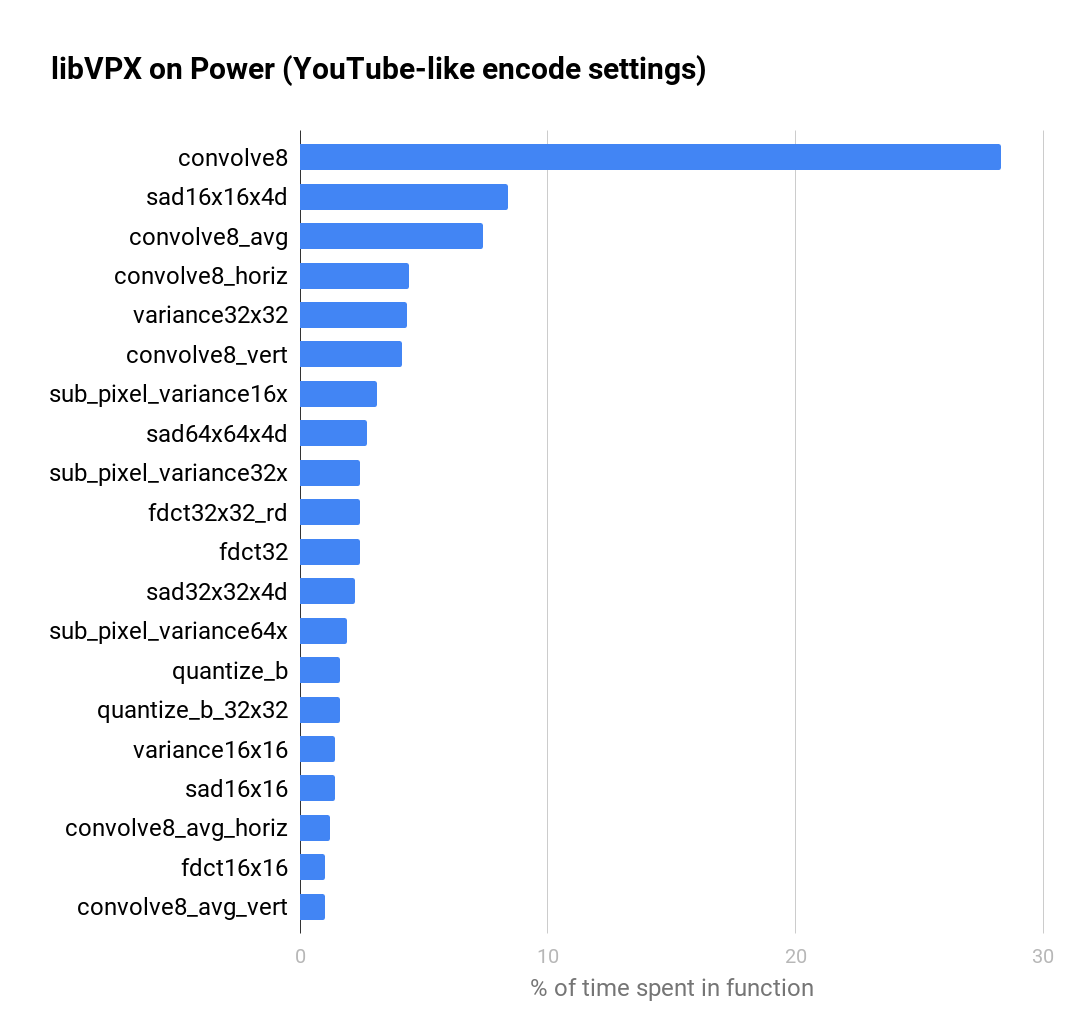
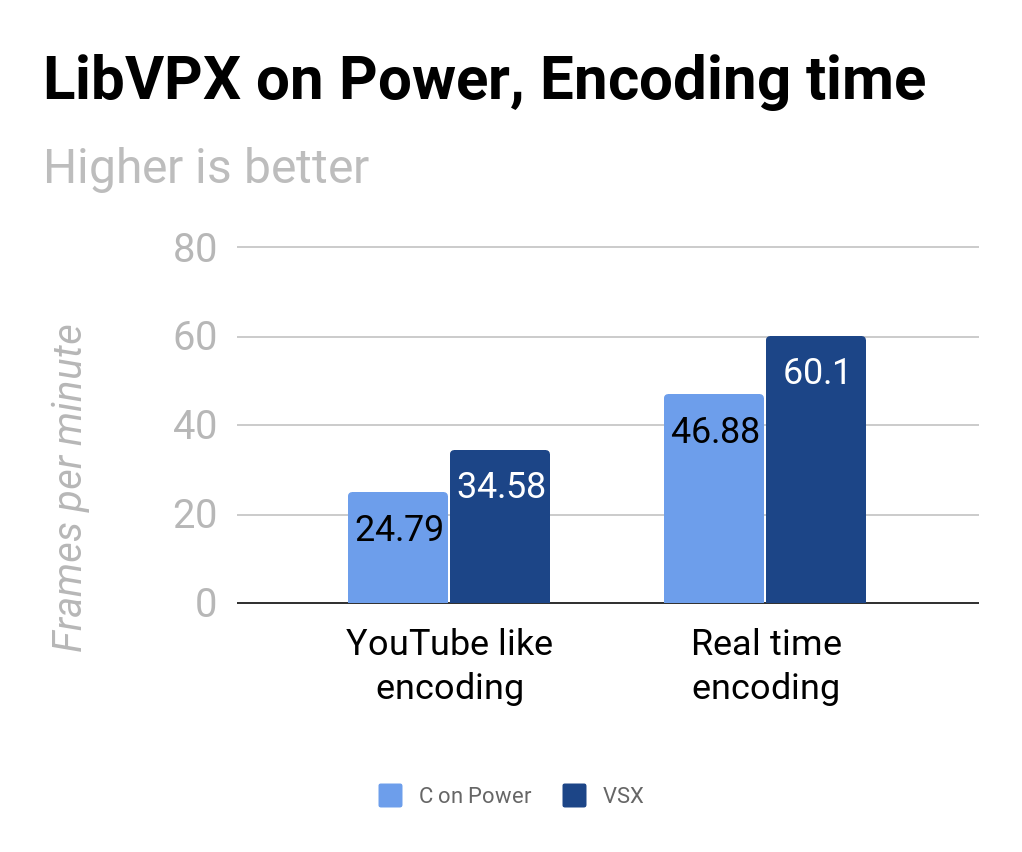
Recently I presented my new project at Fosdem and since I was afraid of not having enough time for the questions I trimmed the content to the bare minimum. This blog post should add some more details.
What is it?
Rust-av aims to be a complete multimedia toolkit written in rust.
Rust is a quite promising language that aims to offer high execution speed while granting a number of warranties on the code behavior that you cannot have in C, C++, Java and so on.
Its zero-cost abstraction feature coupled with the fact that the compiler actively prevents you from committing a large class of mistakes related to memory access seems a perfect match to implement a multimedia toolkit that is easy to use, fast enough and trustworthy.
Why something completely new?
Since rust code can be intermixed with C code, an evolutive approach of replacing little by little small components in a larger project is perfectly feasible, and it is what we are currently trying to do with vlc.
But rust is not just good to write some inner routines so they are fast and correct, its trait system is also quite useful to have a more expressive API.
Most of the multimedia concepts are pretty simple at the high level (e.g frame is just a picture or some sound with some timestamp) with an excruciating amount of quirk and details that require your toolkit to make choices for you or make you face a large amount of complexity.
That leads to API that are either easy but quite inflexible (and opinionated) or API providing all the flexibility, but forcing the user to have to learn a lot of information in order to achieve what the simpler API would let you implement in an handful of lines of code.
I wanted to leverage Rust to make the low level implementations with less bugs and, at the same time, try to provide a better API to use it.
Why now?
Since 2016 I kept bouncing ideas with Kostya and Geoffroy but between my work duties and other projects I couldn’t devote enough time to it. Thanks to the Mozilla Open Source Support initiative that awarded me with enough to develop it full time, now the project has already some components published and more will follow during the next months.
Philosophy
I’m trying to leverage the experience I have from contributing to vlc and libav and keep what is working well and try to not make the same mistakes.
Ease of use
I want that the whole toolkit to be useful to a wide audience. Developers often fight against the library in order to undo what is happening under the hood or end up vendoring some part of it since they need only a tiny subset of all the features that are provided.
Rust makes quite natural split large projects in independent components (called crates) and it is already quite common to have meta-crates re-exporting many smaller crates to provide some uniform access.
The rust-av code, as opposed to the rather monolithic approach taken in Libav, can be reused with the granularity of the bare codec or format:
- Integrating it in a foreign toolkit won’t require to undo what the common utility code does.
- Even when using it through the higher level layers, rust-av won’t force the developer to bring in any unrelated dependencies.
- On the other hand users that enjoy a fully integrated and all-encompassing solution can simply depend on the meta-crates and get the support for everything.
Speed
Multimedia playback boils down to efficiently do complex computation so an arbitrary large amount of data can be rendered within a fraction of second, multimedia real time streaming requires to compress an equally large amount of data in the same time.
Speed in multimedia is important.
Rust provides high level idiomatic constructs that surprisingly lead to pretty decent runtime speed. The stdsimd effort and the seamless C ABI support make easier to leverage the SIMD instructions provided by the recent CPU architectures.
Trustworthy
Traditionally the most effective way to write fast multimedia code had been pairing C and assembly. Sadly the combination makes quite easy to overlook corner cases and have any kind of memory hazards (use-after-free, out of bound reads and writes, NULL-dereferences…).
Rust effectively prevents a good deal of those issues at compile time. Since its abstractions usually do not cause slowdowns it is possible to write code that is, arguably, less misleading and as fast.
Structure
The toolkit is composed of multiple, loosely coupled, crates. They can be grouped by level of abstraction.
Essential
av-data: Used by nearly all the other crates it provides basic data types and a minimal amount of functionality on top of it. It provides the following structs mainly:
- Frame: it binds together a time reference and a buffer, representing either a video picture or some audio samples.
- Packet: it bind together a time reference and a buffer, containing compressed data.
- Value: Simple key value type abstraction, used to pass arbitrary data to the configuration functions.
Core
They provide the basic abstraction (traits) implemented by specific set of components.
- av-format: It provides a set of traits to implement muxers and demuxers and an utility Context to bridge the normal rust I/O Write and Read traits and the actual muxers and demuxers.
- av-codec: It provides a set of traits to implement encoders and decoders and an utility Context that wraps.
Utility
They provide building blocks that may be used to implement actual codecs and formats.
- av-bitstream: Utility crate to write and read bits and bytes
- av-audio: Audio-specific utilities
- av-video: Video-specific utilities
Implementation
Actual implementations of codec and format, they can be used directly or through the utility Contexts.
The direct usage is suggested only if you are integrating it in larger frameworks that already implement, possibly in different ways, the integration code provided by the Context (e.g. binding it together with the I/O for the formats or internal queues for the codecs).
Higher-level
They provide higher level Contexts to playback or encode data through a simplified interface:
- av-player reads bytes though a provided Read and outputs decoded Frames. Under the hood it probes the data, allocates and configures a Demuxer and a Decoder for each stream of interest.
- av-encoder consumes Frames and outputs encoded and muxed data through a Write output. It automatically setup the encoders and the muxer.
Meta-crates
They ease the use in bulk of everything provided by rust-av.
There are 4 crates providing a list of specific components: av-demuxers, av-muxers, av-decoders and av-encoders; and 2 grouping them by type: av-formats and av-codecs.
Their use is suggested when you’d like to support every format and codec available.
So far
All the development happens on the github organization and so far the initial Core and Essential crates are ready to be used.
There is a nom-based matroska demuxer in working condition and some non-native wrappers providing implementations for some decoders and encoders.
Thanks to est31 we have native vorbis support.
I’m working on a native implementation of opus and soon I’ll move to a video codec.
There is a tiny player called avp and an encoder tool (named ave) will appear once the matroska muxer is complete.
What’s missing in rust-av
API-wise, right now rust-av provides only for simple decode and encoding, muxing and demuxing. There are already enough wrapped codecs to let people play with the library and, hopefully, help in polishing it.
For each crate I’m trying to prepare some easy tasks so people willing to contribute to the project can start from them, all help is welcome!
What’s missing in rust
So far my experience with rust had been quite positive, but there are a number of features that are missing or that could be addressed.
- SIMD support is shaping up nicely and it is coming soon.
- The natural fallback, going down to assembly, is available since rust supports the C ABI, inline assembly support on the other hand seems that is still pending some discussion before it reaches stable.
- Arbitrarily aligned allocation is a MUST in order to support hardware acceleration and SIMD works usually better with aligned buffers.
- I’d love to have const generics now, luckily associated constants with traits allow some workarounds that let you specialize by constants (and result in neat speedups).
- I think that focusing a little more on array/slice support would lead to the best gains, since right now there isn’t an equivalent to
collect() to fill arrays in an idiomatic way and in multimedia large lookup tables are pretty much a staple.
In closing
Rust and Multimedia seem a really good match, in my experience beside a number of missing features the language seems quite good for the purpose.
Once I have more native implementations complete I will be able to have better means to evaluate the speed difference from writing the same code in C.