I’m involved in implementing the Altivec and VSX support on rust stdsimd.
Supporting all the instructions in this language is a HUGE endeavor since for each instruction at least 2 tests have to be written and making functions type-generic gets you to the point of having few pages of implementation (that luckily desugars to the single right instruction and nothing else).
Since I’m doing this mainly for my multimedia needs I have a short list of instructions I find handy to get some code written immediately and today I’ll talk a bit about some of them.
This post is inspired by what Luc did for neon, but I’m using rust instead.
If other people find it useful, I’ll try to write down the remaining istructions.
Permutations
Most if not all the SIMD ISAs have at least one or multiple instructions to shuffle vector elements within a vector or among two.
It is quite common to use those instructions to implement matrix transposes, but it isn’t its only use.
In my toolbox I put vec_perm and vec_xxpermdi since even if the portable stdsimd provides some shuffle support it is quite unwieldy compared to the Altivec native offering.
vec_perm: Vector Permute
Since it first iteration Altivec had a quite amazing instruction called vec_perm or vperm:
fn vec_perm(a: i8x16, b: i8x16, c: i8x16) -> i8x16 { let mut d; for i in 0..16 { let idx = c[i] & 0xf; d[i] = if (c[i] & 0x10) == 0 { a[idx] } else { b[idx] }; } d }
It is important to notice that the displacement map c is a vector and not a constant. That gives you quite a bit of flexibility in a number of situations.
This instruction is the building block you can use to implement a large deal of common patterns, including some that are also covered by stand-alone instructions e.g.:
– packing/unpacking across lanes as long you do not have to saturate: vec_pack, vec_unpackh/vec_unpackl
– interleave/merge two vectors: vec_mergel, vec_mergeh
– shift N bytes in a vector from another: vec_sld
It can be important to recall this since you could always take two permutations and make one, vec_perm itself is pretty fast and replacing two or more instructions with a single permute can get you a pretty neat speed boost.
vec_xxpermdi Vector Permute Doubleword Immediate
Among a good deal of improvements VSX introduced a number of instructions that work on 64bit-elements vectors, among those we have a permute instruction and I found myself using it a lot.
#[rustc_args_required_const(2)] fn vec_xxpermdi(a: i64x2, b: i64x2, c: u8) -> i64x2 { match c & 0b11 { 0b00 => i64x2::new(a[0], b[0]); 0b01 => i64x2::new(a[1], b[0]); 0b10 => i64x2::new(a[0], b[1]); 0b11 => i64x2::new(a[1], b[1]); } }
This instruction is surely less flexible than the previous permute but it does not require an additional load.
When working on video codecs is quite common to deal with blocks of pixels that go from 4×4 up to 64×64, before vec_xxpermdi the common pattern was:
#[inline(always)] fn store8(dst: &mut [u8x16], v: &[u8x16]) { let data = dst[i]; dst[i] = vec_perm(v, data, TAKE_THE_FIRST_8); }
That implies to load the mask as often as needed as long as the destination.
Using vec_xxpermdi avoids the mask load and that usually leads to a quite significative speedup when the actual function is tiny.
Mixed Arithmetics
With mixed arithmetics I consider all the instructions that do in a single step multiple vector arithmetics.
The original altivec has the following operations available for the integer types:
– vec_madds
– vec_mladd
– vec_mradds
– vec_msum
– vec_msums
– vec_sum2s
– vec_sum4s
– vec_sums
And the following two for the float type:
– vec_madd
– vec_nmsub
All of them are quite useful and they will all find their way in stdsimd pretty soon.
I’m describing today vec_sums, vec_msums and vec_madds.
They are quite representative and the other instructions are similar in spirit:
– vec_madds, vec_mladd and vec_mradds all compute a lane-wise product, take either the high-order or the low-order part of it
and add a third vector returning a vector of the same element size.
– vec_sums, vec_sum2s and vec_sum4s all combine an in-vector sum operation with a sum with another vector.
– vec_msum and vec_msums both compute a sum of products, the intermediates are added together and then added to a wider-element
vector.
If there is enough interest and time I can extend this post to cover all of them, for today we’ll go with this approximation.
vec_sums: Vector Sum Saturated
Usually SIMD instruction work with two (or 3) vectors and execute the same operation for each vector element.
Sometimes you want to just do operations within the single vector and vec_sums is one of the few instructions that let you do that:
fn vec_sums(a: i32x4, b: i32x4) -> i32x4 { let d = i32x4::new(0, 0, 0, 0); d[3] = b[3].saturating_add(a[0]).saturating_add(a[1]).saturating_add(a[2]).saturating_add(a[3]); d }
It returns in the last element of the vector the sum of the vector elements of a and the last element of b.
It is pretty handy when you need to compute an average or similar operations.
It works only with 32bit signed element vectors.
vec_msums: Vector Multiply Sum Saturated
This instruction sums the 32bit element of the third vector with the two products of the respective 16bit
elements of the first two vectors overlapping the element.
It does quite a bit:
fn vmsumshs(a: i16x8, b: i16x8, c: i32x4) -> i32x4 { let d; for i in 0..4 { let idx = 2 * i; let m0 = a[idx] as i32 * b[idx] as i32; let m1 = a[idx + 1] as i32 * b[idx + 1] as i32; d[i] = c[i].saturating_add(m0).saturating_add(m1); } d } fn vmsumuhs(a: u16x8, b: u16x8, c: u32x4) -> u32x4 { let d; for i in 0..4 { let idx = 2 * i; let m0 = a[idx] as u32 * b[idx] as u32; let m1 = a[idx + 1] as u32 * b[idx + 1] as u32; d[i] = c[i].saturating_add(m0).saturating_add(m1); } d } ... fn vec_msums<T, U>(a: T, b: T, c: U) -> U where T: sealed::VectorMultiplySumSaturate<U> { a.msums(b, c) }
It works only with 16bit elements, signed or unsigned. In order to support that on rust we have to use some creative trait.
It is quite neat if you have to implement some filters.
vec_madds: Vector Multiply Add Saturated
fn vec_madds(a: i16x8, b: i16x8, c: i16x8) -> i16x8 { let d; for i in 0..8 { let v = (a[i] as i32 * b[i] as i32) >> 15; d[i] = (v as i16).saturating_add(c[i]); } d }
Takes the high-order 17bit of the lane-wise product of the first two vectors and adds it to a third one.
Coming next
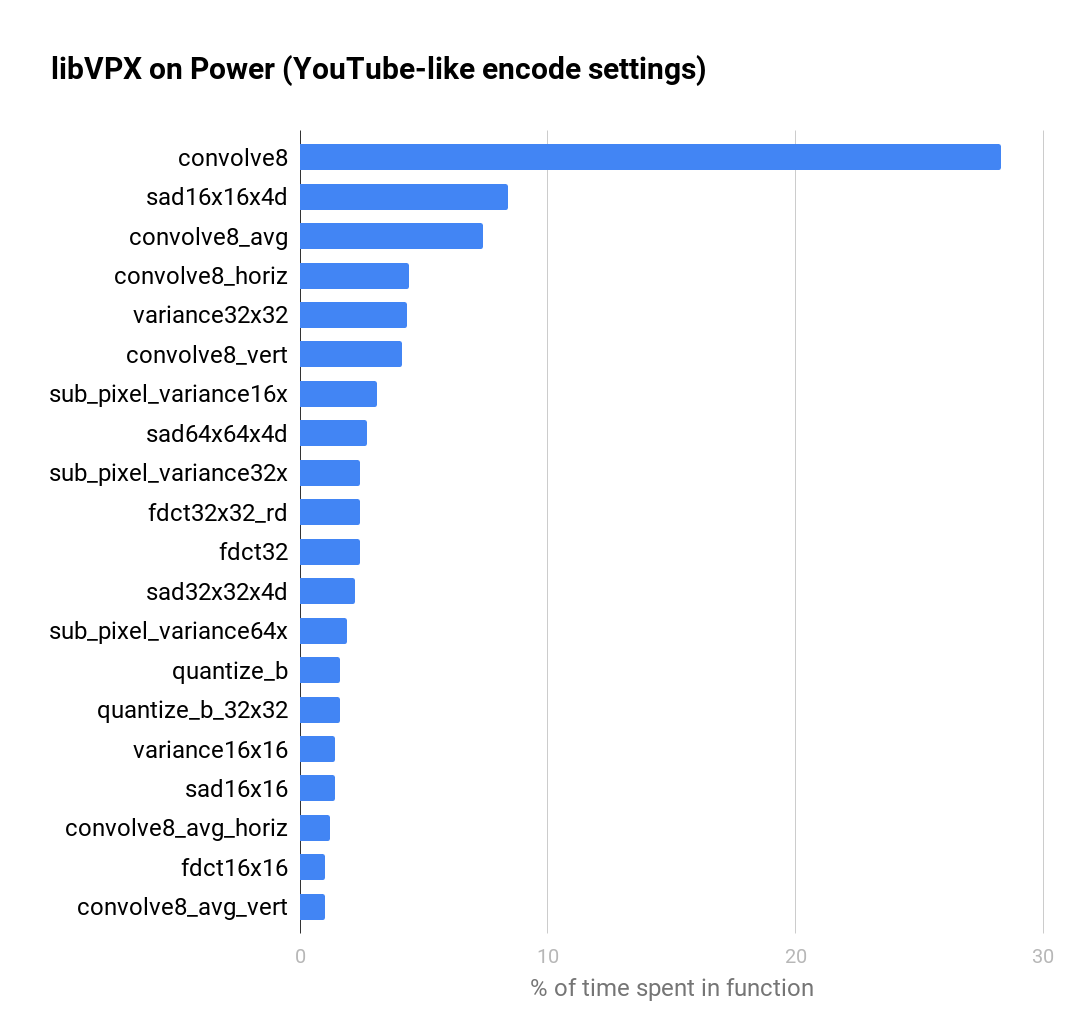
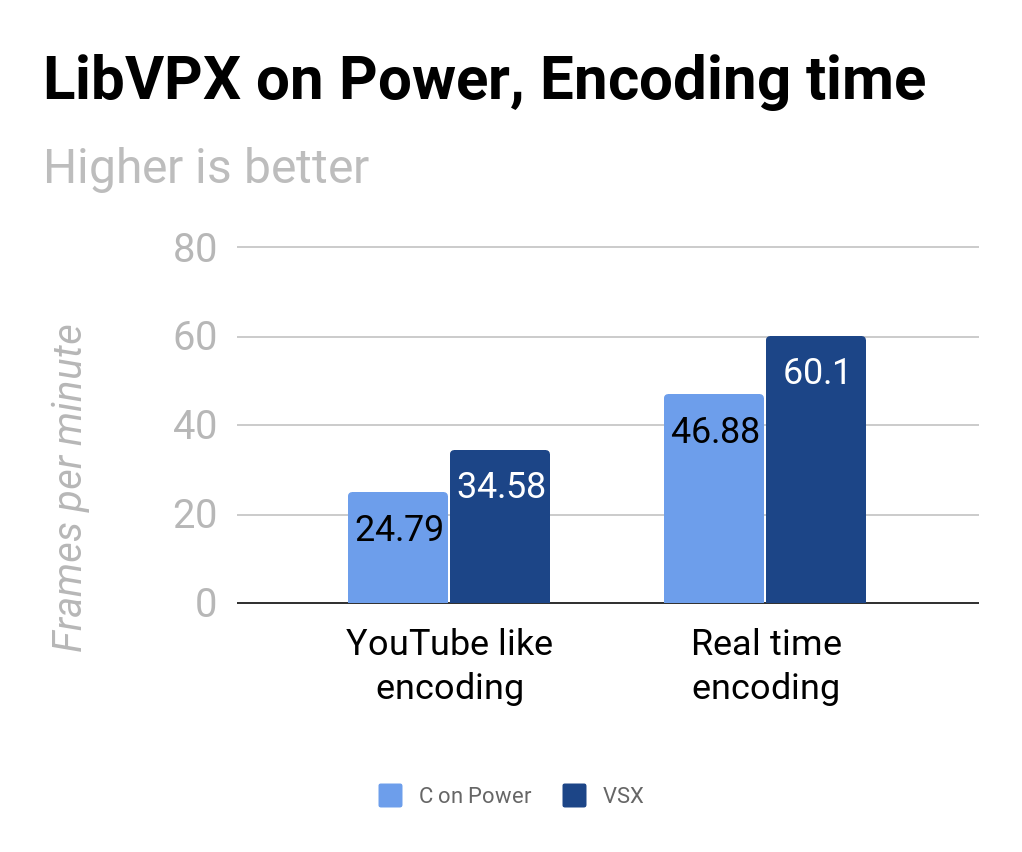
Raptor Enginering kindly gave me access to a Power 9 through their Integricloud hosting.
We could run some extensive benchmarks and we found some peculiar behaviour with the C compilers available on the machine and that got me, Luc and Alexandra a little puzzled.
Next time I’ll try to collect in a little more organic way what I randomly put on my twitter as I noticed it.