In this post, we (Luca Barbato and Luc Trudeau) joined forces to talk about the awesome work we’ve been doing on Altivec/VSX optimizations for the libvpx library, you can read it here or on Luc’s medium.
Both of us where in Brussels for FOSDEM 2018, Luca presented his work on rust-av and Luc was there to hack on rav1e – an experimental AV1 video encoder in Rust.
Luca joined the rav1e team and helped give hints about how to effectively leverage rust. Together, we worked on AV1 intra prediction code, among the other things.
Luc Trudeau: I was finishing up my work on Chroma from Luma in AV1, and wanted to stay involved in royalty free open source video codecs. When Luca talked to me about libvpx bounties on Bountysource, I was immediately intrigued.
Luca Barbato: Luc just finished implementing the Neon version of his CfL work and I wondered how that code could work using VSX. I prepared some of the machinery that was missing in libaom and Luc tried his hand on Altivec. We still had some pending libvpx work sponsored by IBM and I asked him if he wanted to join in.
What’s libvpx?
For those less familiar, libvpx is the official Google implementation of the VP9 video format. VP9 is most notably used in YouTube and Netflix. VP9 playback is available on some browsers including Chrome, Edge and Firefox and also on Android devices, covering the 75.31% of the global user base.
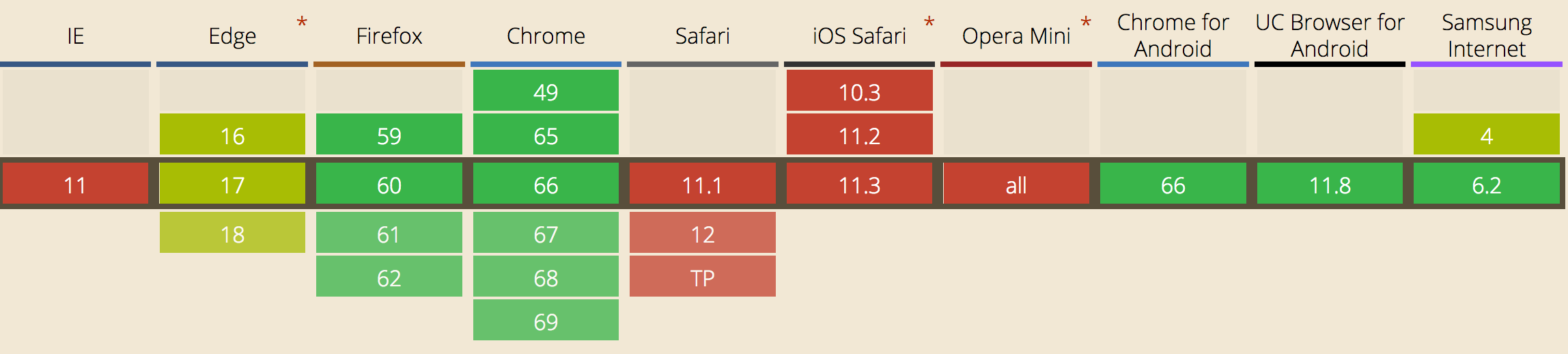
Ref: caniuse.com VP9 support in browsers.
Why use VP9, when the de facto video format is H.264/AVC?
Because VP9 is royalty free and the bandwidth savings are substantial when compared to H.264 when playback is available (an estimated 3.3B devices support VP9). In other words, having VP9 as a secondary codec can pay for itself in bandwidth savings by not having to send H.264 to most users.
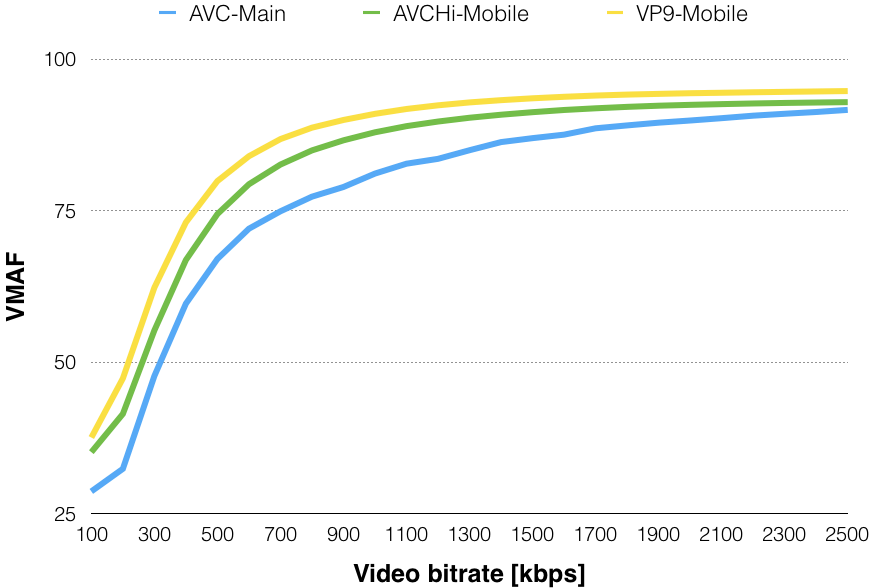
Ref: Netflix VP9 compression analysis.
Why care about libvpx on Power?
Dynamic adaptive streaming formats like HLS and MPEG DASH have completely changed the game of streaming video over the internet. Streaming hardware and custom multimedia servers are being replaced by web servers.
From the servers’ perspective streaming video is akin to serving small videos files; lots of small video files! To cover all clients and most network conditions a considerable amount of video files must be encoded, stored and distributed.
Things are changing fast and while the total cost of ownership of video content for previous generation video formats, like H.264, was mostly made up of bandwidth and hosting, encoding costs are growing with more complex video formats like HEVC and VP9.
This complexity is reported to have grown exponentially with the upcoming AV1 video format. A video format, built on the libVPX code base, by the Alliance for Open Media, of which IBM is a founding member.
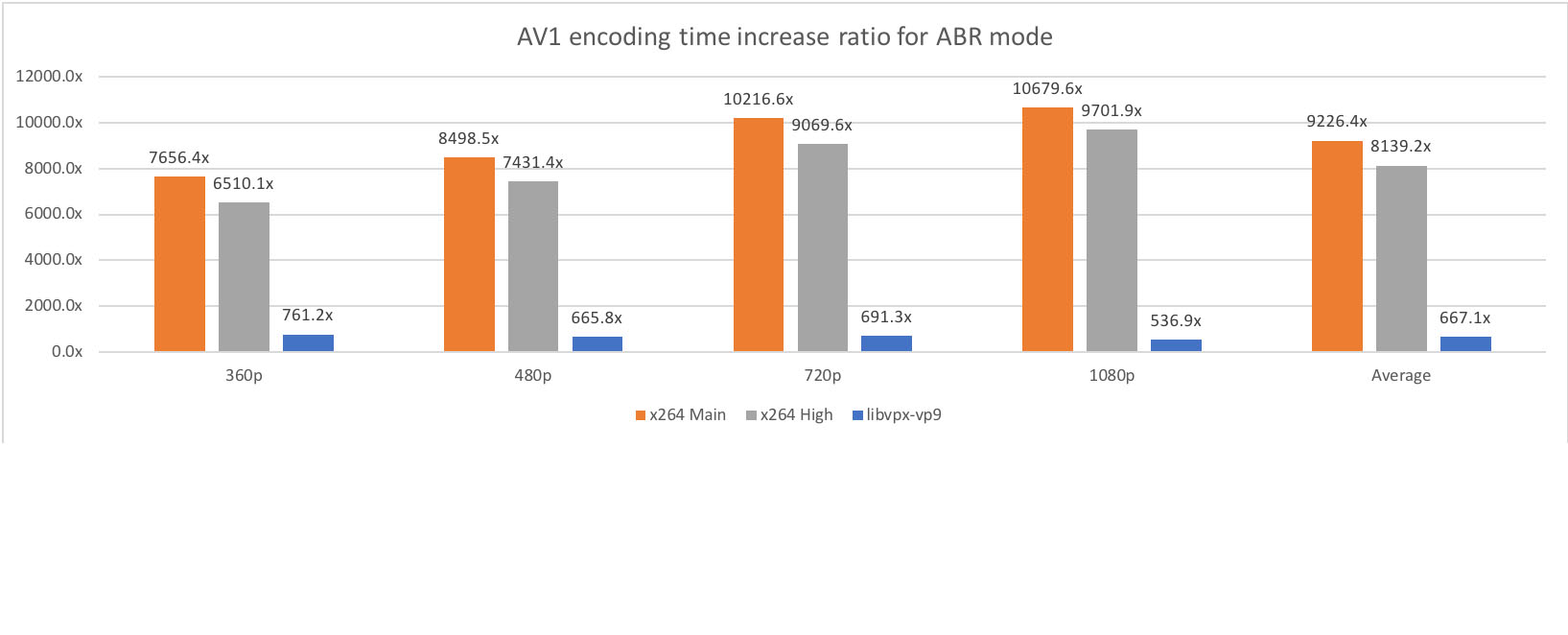
Ref: Facebook’s AV1 complexity analysis
At the same time, IBM and its partners in the OpenPower Foundation are releasing some very impressive hardware with the new Power9 processor line up. Big Iron Power9 systems, like the Talos II from Raptor Computing Systems and the collaboration between Google and Rackspace on Zaius/Barreleye servers, are ideal solutions to the tackle the growing complexity of video format encoding.
However, these awesome machines are currently at a disadvantage when encoding video. Without the platform specific optimizations, that their competitors enjoy, the Power9 architecture can’t be fully utilized. This is clearly illustrated in the x264 benchmark released in a recent Phoronix article.
Ref: Phoronix x264 server benchmark.
Thanks to the optimization bounties sponsored by IBM, we are hard at work bridging the gap in libvpx.
Optimization bounties?
Just like bug bounty programs, optimization make for great bounties. Companies that see benefit in platform specific optimizations for video codecs can sponsor our bounties on the Bountysource platform.
Multiple companies can sponsor the same bounty, thus sharing cost of more important bounties. Furthermore, bounties are a minimal risk investment for sponsors, as they are only paid out when the work is completed (and peer reviewed by libvpx maintainers)
Not only is the Bountysource platform a win for companies that directly benefit from the bounties they are sponsoring, it’s also a win for developers (like us) who can get paid to work on free and open source projects that we are passionate about. Optimization bounties are a source of sustainability in the free and open source software ecosystem.
How do you choose bounties?
Since we’re a small team of bounty hunters (Luca Barbato, Alexandra Hájková, Rafael de Lucena Valle and Luc Trudeau), we need to play it smart and maximize the impact of our work. We’ve identified two common use cases related to streaming on the Power architecture: YouTube-like encodes and real time (a.k.a. low latency) encodes.
By profiling libvpx under these conditions, we can determine the key functions to optimize. The following charts show the percentage of time spent the in top 20 functions of the libvpx encoder (without Altivec/VSX optimisations) on a Power8 system, for both YouTube-like and real time settings.
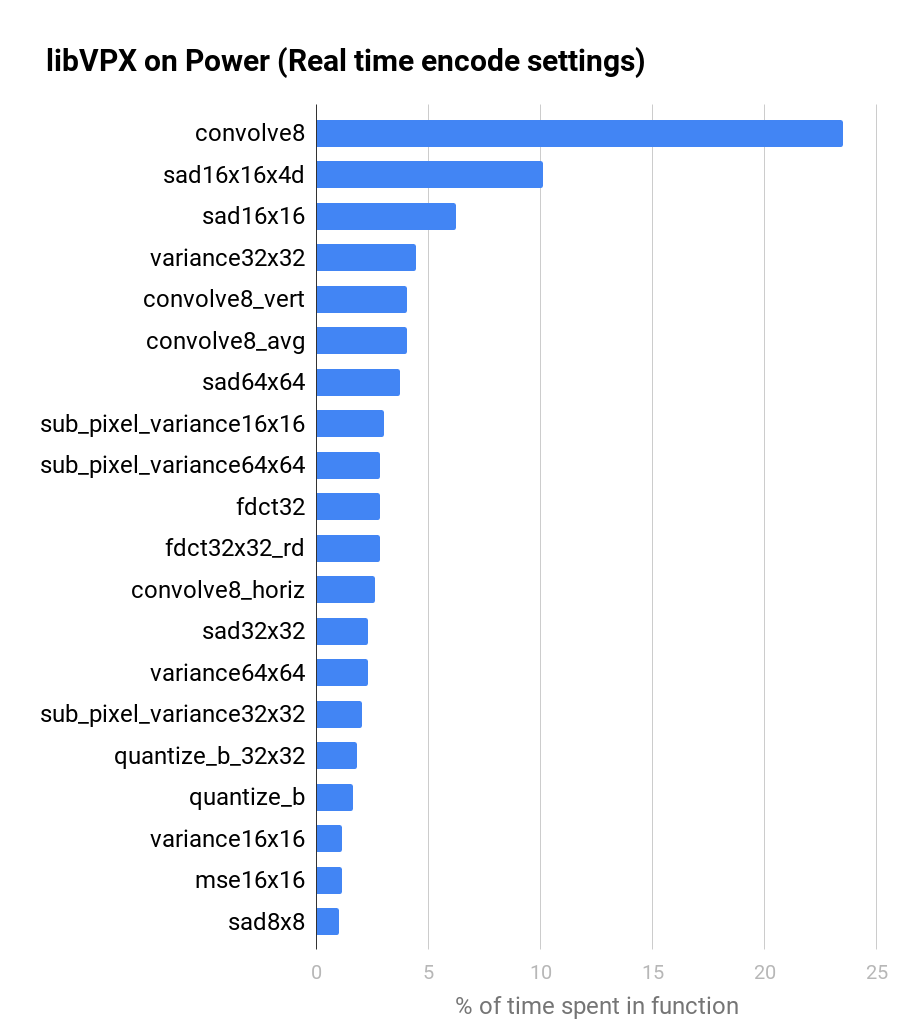
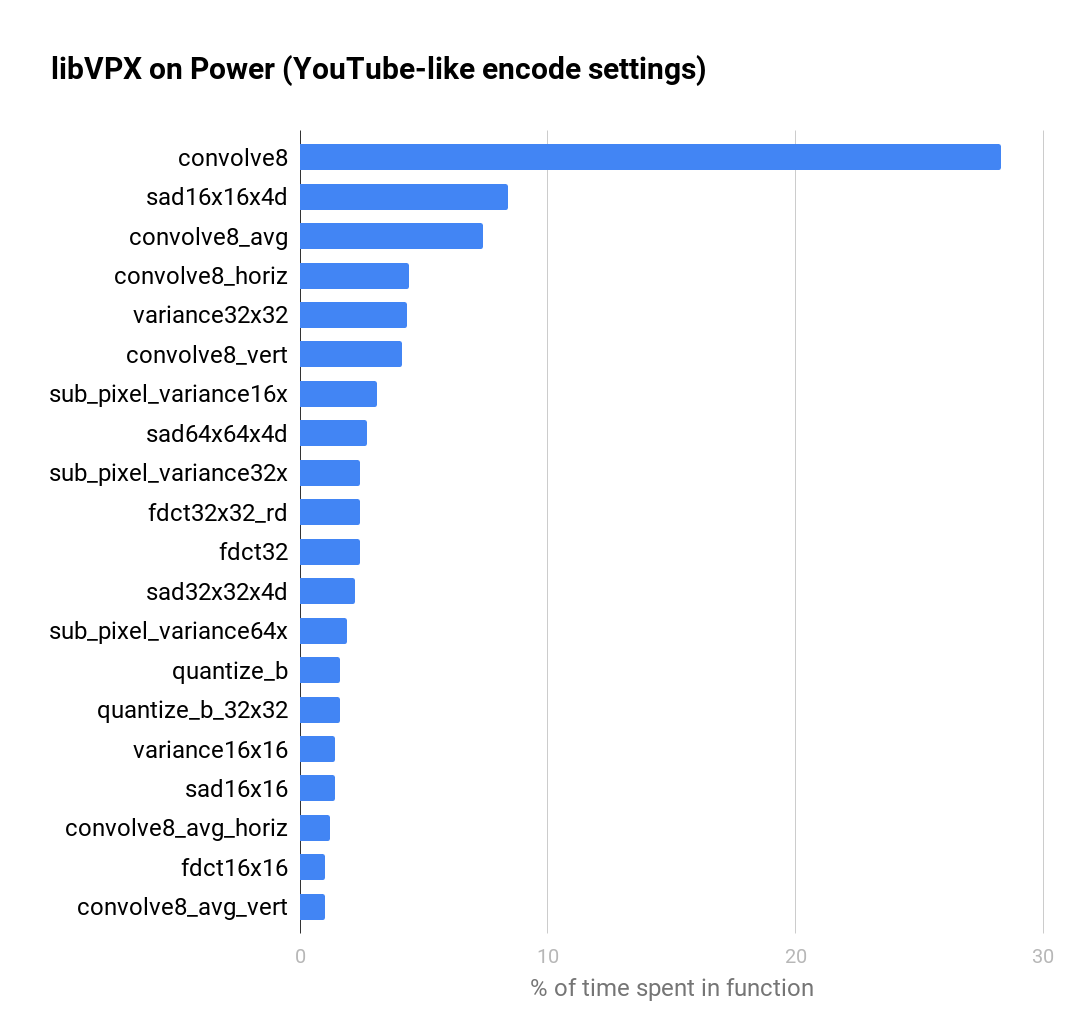
It’s interesting to see that the top 20 functions make up about 80% of the encoding time. That’s similar in spirit to the Pareto principle, in that we don’t have to optimize the whole encoder to make the Power architecture competitive for video encoding.
We see a similar distribution between YouTube-like encoding settings and real time video encoding. In other words, optimization bounties for libvpx benefit both Video on Demand (VOD) and live broadcast services.
We add bounties on the Bountysource platform around common themed functions like: convolution, sum of absolute differences (SAD), variance, etc. Companies interested in libvpx optimization can go and fund these bounties.
What’s the impact of this project so far?
So far, we delivered multiple libvpx bounties including:
- Convolution
- Sum of absolute differences (SAD)
- Quantization
- Inverse transforms
- Intra prediction
- etc.
To see the benefit of our work, we compiled the latest version of libVPX with and without VSX optimizations and ran it on a Power8 machine. Note that the C compiled versions can produce Altivec/VSX code via auto vectorization. The results, in frames per minutes, are shown below for both YouTube-like encoding and Real time encoding.
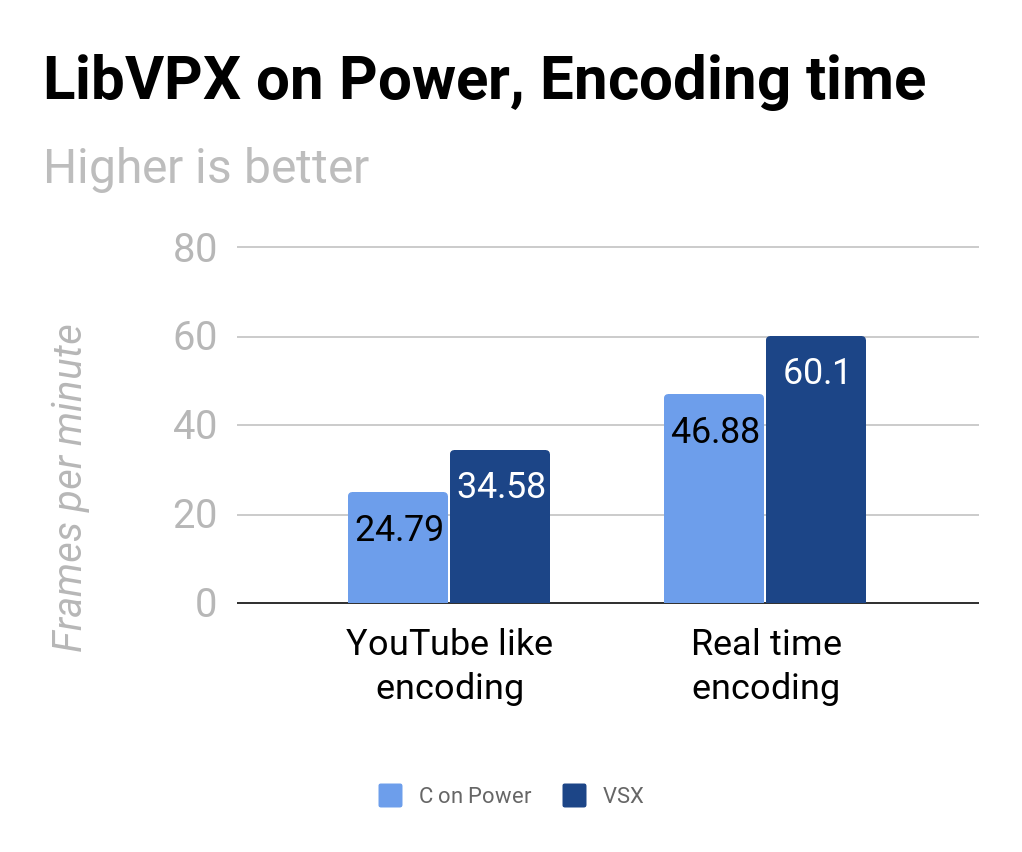
Our current VSX optimizations give approximately a 40% and 30% boost in encoding speed for YouTube-like and real time encoding respectively. Encoding speed increases in the range of 10 to 14 frames per minute can considerably reduce cloud encoding costs for Power architecture users.
In the context of real time encoding, the time saved by the platform optimization can be put to good use to improve compression efficiency. Concretely, a real time encoder will encode in real time speed, but speeding up the encoders allows for operators to increase the number of coding tools, resulting in better quality for the viewers and bandwidth savings for operators.
What’s next?
We’re energized by the impact that our small team of bounty hunters is having on libvpx performance for the Power architecture and we wanted to share it in this blog post. We look forward to getting even more performance from libvpx on the Power architecture. Expect considerable performance improvement for the Power architecture in the next libvpx release (1.8).
As IBM targets its Power9 line of systems at heavy cloud computations, it seems natural to also aim all that power at tackling the growing costs of AV1 encodes. This won’t happen without platform specific optimizations and the time to start is now; as the AV1 format is being finalized, everyone is still in the early phases of optimization. We are currently working with our sponsors to set up AV1 bounties, so stay tuned for an upcoming post.