¡Al fin! Lo que todos estabamos esperando. La tan ansiada guía de instalación de Gentoo Linux, hecha por mí, tomando referencias del Handbook de Gentoo. Antes de empezar a contar los pasos y ver si pude cumplir con mi promesa de mantenerlo simple, deseo hacer un par de aclaraciones.
Esta guía es lo más simple posible
No pretendo enseñarles cómo instalar el último driver NVIDIA, o el último filesystem experimental de alguna empresa. Intentaré dejar todo en lo mínimo de lo funcional, ¿por qué? sencillo, así les dejo algo a ustedes para investigar y aprender ;)
Los pasos de instalación
Voy a resumir de forma muy sencilla los bloques en los que voy a trabajar durante esta guía. Pienso instalar Gentoo en un usb para tomar las caputaras de pantalla, pero pueden replicarlo en su disco duro y seguir conmigo el proceso. Los pasos son los siguientes:
- Medio de instalación.
- Preparar discos.
- Stage3
- Make.conf
- Chroot
- Kernel
- Grub
- Disfrutar :)
Como pueden ver yo difiero un poco del handbook, pero es porque prefiero juntar todo dentro del mismo paquete para poder realizar un trabajo más limpio, pero en caso de necesitar detenerse a revisar otras opciones no duden en ir al Handbook, ahí estará toda la información que puedan necesitar.
Para esta instalación estaré usando SystemD y GNOME ( explicaré los cambios necesarios para KDE dentro del apartado de GNOME), pero para los aventureros de OpenRC, pues tendrán que hacer su tarea ;) escojo SystemD por lo que ha sido adoptado por muchos otros sistemas y tal vez les sea más familiar a la hora de configurar ciertas cosas mientras van cogiendo experiencia con Gentoo. Sin más que agregar, empecemos:
Medio de instalación:
Les dejo aquí el link de mi anterior post sobre este tema, les recomiendo utilizar una distro que ya tenga entorno gráfico, puesto que es más sencillo revisar el Handbook de esta manera, y siempre se puede repetir todo desde cualquier parte con mayor facilidad. Yo lo haré desde mi Gentoo de siempre con la que escribo estos posts.
Preparar los discos:
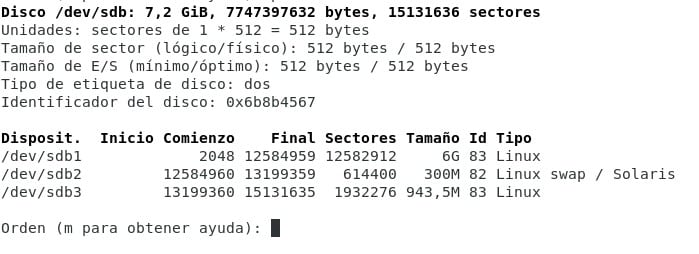
Este paso siempre es muy personal, y en realidad siempre es un momento para reflexionar y detenerse a ver cómo deseas que termine tu partición. Como hemos dicho que vamos a mentenerlo simple, no vamos a usar LVM ni RAID, sino simple y puro ext4 en nuestras particiones. yo voy a formatear el usb que es el dispositivo /dev/sdb, evidentemente tienes que acomodarlo a tus necesidades.

Como podrán ver estoy usando fdisk porque pretendo usar MBR para mi sistema, otra tarea por resolver para los que deseen usar UEFI ;)
Crearé un swap simbólico y una partición simbólica home solo para que puedan seguir el paso más sencillo. /boot lo voy a dejar en el directorio raíz porque como mencionamos, lo mantendremos simple. (Ya vamos 1 comando)
Terminaré con una estructura parecida a esta:
terminaremos con w para escribir el disco. Dependiendo de las particiones que hayas hecho y los tipos de filesystem que hayas colocado, tendremos que crearlos con mkfs. Algo como esto:
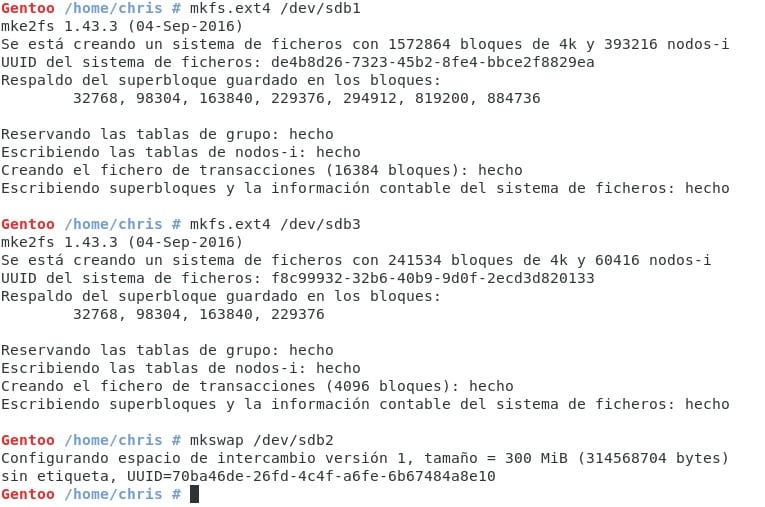
(Este lo contaré como un solo comando porque es repetitivo ;) (Ya vamos 2 pasos).
Ahora vamos a montar nuestro nuevo sistema dentro de el sistema que ya está encendido. Para esto usamos la herramienta mount. (yo creé el directorio /mnt/gentoo, pero eso puede omitirse) (Ya vamos 3 pasos.)

Con esto ya tenemos el sistema preparado para el siguiente paso.
Stage3:
El stage3 es un comprimido que se descarga desde la página oficial de Gentoo, puedes descargarlo en tu navegador o desde consola, por temas de practicidad yo usaré uno que ya tengo descargado y lo ubicaré en la posición donde monté el sistema (/mnt/gentoo). (Ya vamos 4 pasos)

Solo quiero recalcar aquí que estoy descargando un stage3 con systemd ya incluído. Eso me ahorra bastante tiempo de recompilación puesto que ya varios programas vienen prediseñados con systemd y un perfil con systemd. También quité la opción v de tar para que no aparezca la lista gitante de data extraída, pero si la desean ver, pueden agregarla.
Ahora estamos en esta sección del Handbook
Si desean ver cómo queda todo después de descomprimir solo hace falta usar <code>ls</code> en el directorio, y tendrán algo como esto:

Make.conf:
Ya vamos a más de la mitad del camino, ahora solo tenemos que configurar nuestro corazón. Para esto pueden leer la guía de Gentoo, yo solo haré unos cuantos ajustes, les mostraré el antes y el después para que puedan ver cuánto es lo que yo he cambiado.
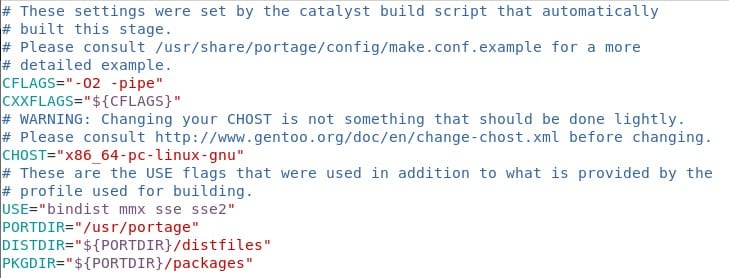
Antes:
Después:
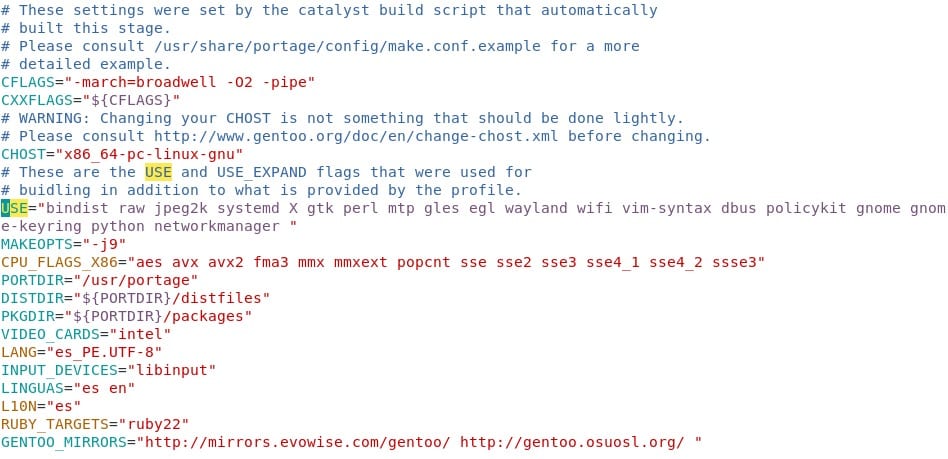
Como pueden apreciar, no es mucho lo que agregas, lo más complicado de averiguar son los CPU_FLAGS_x86 que se pueden poner después de la instalación completa y cuando portage ya esté funcionando. De todas maneras es bueno dar un ojeada al Handbook y revisar los links que aparecen para poder tener más información. La lista de mirrors la dejo aquí por si acaso. Solo elijan el que más les acomode. De nuevo, como lo estamos manteniendo simple, vamos a tratar de no variar mucho las cosas.
Otro pequeño retoque que tenemos que hacer ni bien comienza la instalación es copiar la dirección de nuestro repositorio, esto lo logramos con el siguiente comando (Ya vamos… 5 pasos, 6 contando el que sigue)

Esto lo que hace es copiar la configuración necesaria para que portage pueda descargar el árbol de programas, que es la colección de ebuilds que permiten instalar cualquier paquete en Gentoo.
Con esto ya tenemos lo mínimo necesario para poder empezar a usar Gentoo en consola :)
Chroot
Justo ahora nos encontramos en esta sección del Handbook, vamos a copiar nuestro DNS actual, y montar una conexión entre el kernel que está corriendo y nuestro ambiente Gentoo en la partición. Esto lo vamos a hacer con los siguientes comandos

Cabe resaltar que algunas distribuciones tienen que montar unos cuantos sistemas extra, pero por lo menos las veces que he probado con esto ha sido suficiente. Si tienen dificultades, el Handbook todo lo puede ;). ( Ya vamos como…12 líneas de comando, pero este sería el paso número 7)
Ahora vamos a entrar a nuestro nuevo Gentoo… A partir de aquí ya estamos corriendo el nuevo sistema operativo por consola :D

El último comando es opcional, nos indica simplemente en la terminal que estamos dentro del chroot cambiando el nombre para mejor distinción :) (¡Ya vamos 8!)
Lo primero que vamos a hacer en nuestro nuevo Gentoo es actualizar el repositorio, esto lo logramos con el comando emerge-webrsync. Es normal que aparezcan algunas alertas, es simplemente que se están creando los archivos o direcotorios que antes no existían.
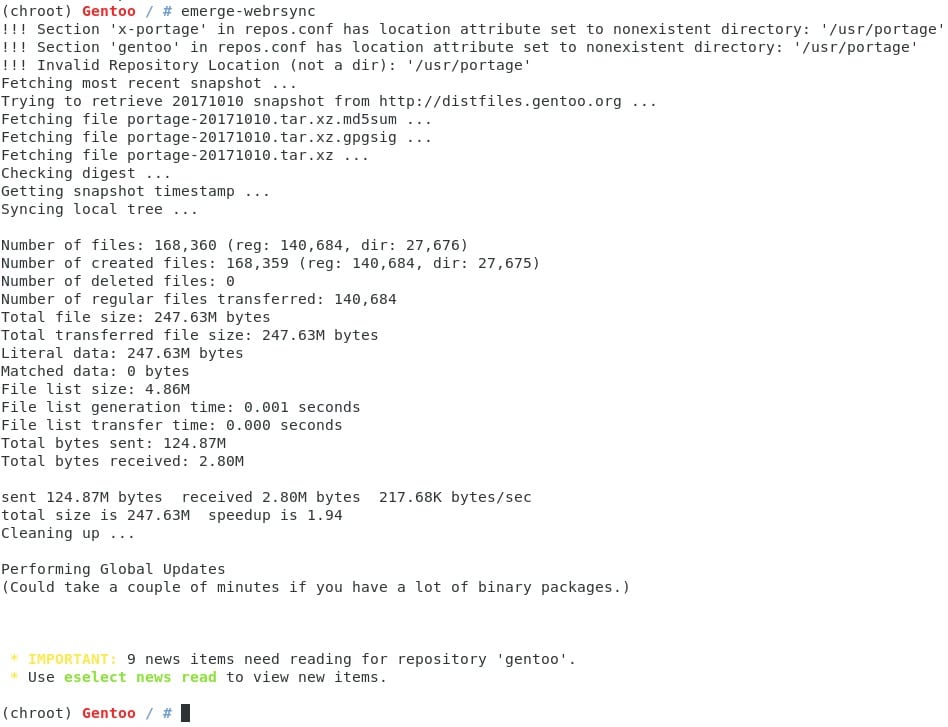
Ahora vamos a configurar unos cuantos detalles antes de actualizar el sistema ( les explico por qué lo hago así en un momento). Primero nuestro perfil, si ya han visto mi post sobre make.conf, habrán podido notar el pequeño extra que dejé sobre los perfiles, ahora es momento de empezar a construir nuestro escritorio preferido, primero revisaremos qué perfil tenemos activo con eselect:
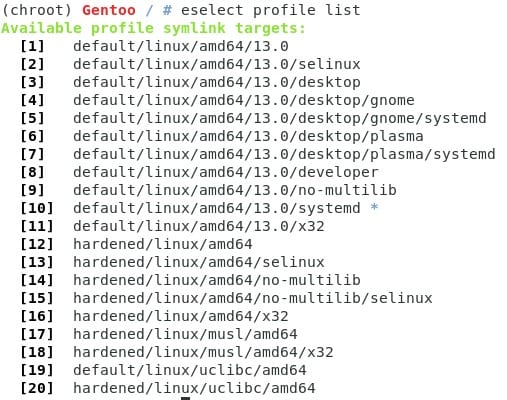
Como podemos ver, contamos con un pefril con amd64 y systemd por defecto (esto se debe a la opción que escogimos de stage3 en la página oficial de descargas). Para seleccionar un perfil podemos usar el número o el nombre, yo pondré gnome con systemd pero si desean kde necesitan escoger plasma. (Si desean otro, pueden dejarlo con el perfil de systemd. (Este es el paso 10 ;) )
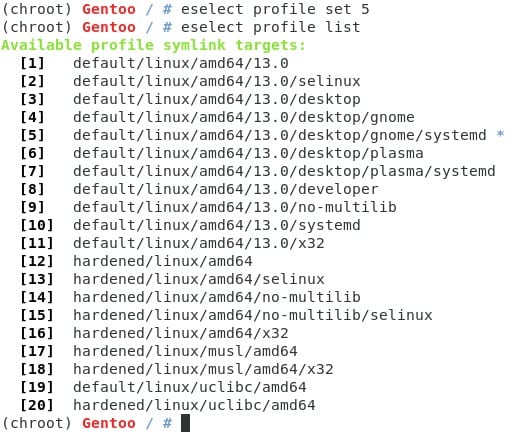
El asterisco (*) indica el perfil seleccionado.
Ahora vamos a descargar unos cuantos programas que nos van a servir para terminar nuestra instalación de manera exitosa. Los escribo todos en el mismo comando para ahorrar números ya que me acerco a los 20 :P pero no se preocupen, los explicaré todos:

Bueno, esta es la lista de programas que estoy instalando (la lista en pantalla es más grande por sus dependencias):
- gentoo-sources: Nuestro conjunto de código fuente para instalar el kernel en el paso siguiente.
- linux-firmware: Muchos drivers necesarios para diversas computadoras (mi driver de wifi se encuentra en esta lista por ejemplo)
- genkernel-next: Herramienta especialmente diseñada para facilitar el proceso de compilación de kernel y creación de initramfs (complejidades que escapan a este post, pero que son necesarias para correr systemd)
- gentoolkit: Conjunto de herramientas de Gentoo que permiten un mejor manejo del sistema.
- grub: Gestor de arranque, muy importante para poder comenzar a usar nuestro sistema.
- vim: Simplemente me gusta más que nano (que es el que viene por defento :P ).
Dependiendo de la conexión a internet y la capacidad del procesador, esto puede tardar un buen tiempo. Tomen este tiempo como referencia para los siguientes pasos. ( Ya vamos 11 :O , falta poco ;) )
Ahora vamos a realizar unas configuraciones menores dentro del sistema:
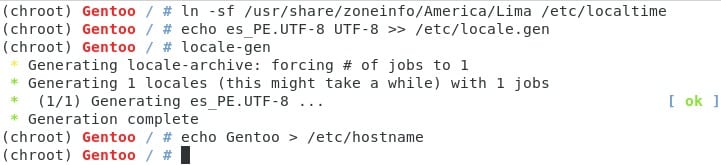
Rápidamente comentando estas líneas por orden:
- Generamos nuestra zona horaria. Normalmente viene en la forma zoneinfo/<Región>/<Ciudad>. Si necesitan ver su ciudad y región pueden dar un ls al directorio.
- Generar nuestras locales. Gentoo viene por defecto con muy pocas locales, siempre es recomendable usar UTF-8 y nosotros lo que hacemos es agregar la de nuestro país a la lista y generar todas las de la lista. En mi caso solo he puesto una para que vean cómo se hace.
- Poner nuestro nombre de host, cualquier nombre basta en este punto ;)
Para los más exigentes… ya vamos por el paso 12 :) ya falta muy poco.
Ahora generaremos el archivo fstab, para los que desconocen su uso, pues a leer en internet ;) pero para darles una idea general, es un archivo que se lee al momento de iniciar el sistema que permite montar todas las particiones en puntos estratégicos del sistema. Por ahora lo vamos a dejar con los valores de nuestras particiones.
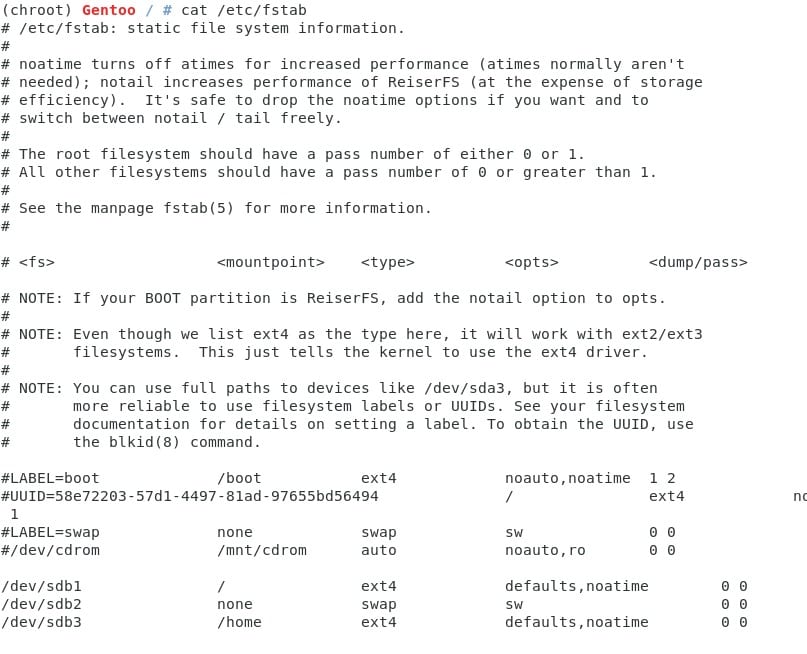
Como podemos apreciar estoy poniendo los discos en que he colocado Gentoo. Probablemente ustedes usarán otros nombres (sda) y la cantidad de opciones y tipos que deseen. (Paso 13)
Ahora pondremos la clave de nuestro usuario root.

Si deseamos, este es un bueno momento para crear nuestro usuario o lo podemos hacer depués, pero recuerden montar su directorio home con la partición correspondiente. (Estos pasos pueden contarse como el número 14)

Esta vez estoy poniendo una clave de prueba, pero no se olviden de asegurar bastante bien a su usuario root y a los demás también. ;)
Ahora que ya hemos terminado con todos los pasos previos, el momento de la verdad…
Kernel
Nuestro kernel será un momento de reflexión y lectura, recomiendo bastante dar un vistazo a la documentación de Gentoo referente al tema, en especial tomaré un par de capturas a unas cuantas partes importantes, vamos adelante:
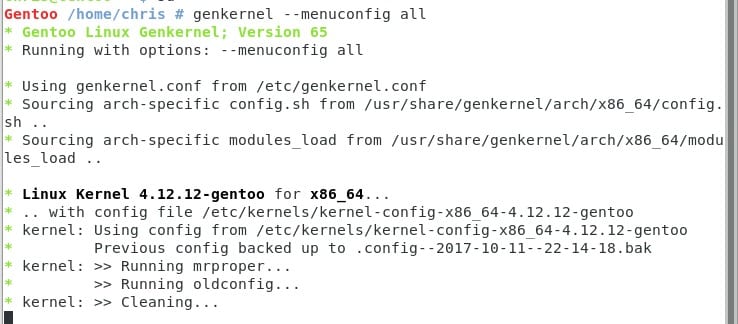
Con esto podremos empezar el proceso de configuración, que para systemd requiere de unos cuantos detalles particulares que mostraré a continuación.
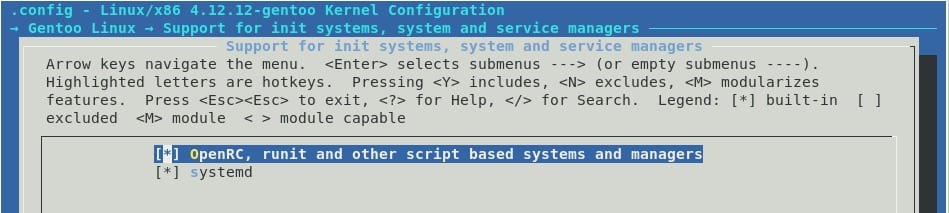
Recuerden que la ruta aparece en la parte de arriba (la segunda línea celeste). Es necesario tener ambos init system como obligatorios <Y> para que se vea como [*].
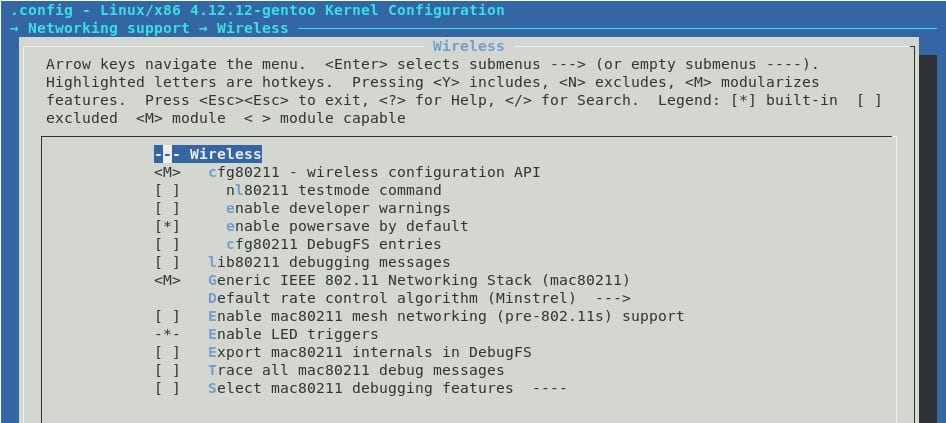
Algunos módulos necesarios para poder trabajar con Wifi. Porque hoy en día todos usamos wifi :) cfg80211, mac80211.

Como podrán observar, mi tarjeta de red wifi es intel :) todo lo demás simplemente no me sirve, al menos no en mi laptop actual. Cada quién tendrá que usar lo que más le convenga. Recuerda que <code>lspci</code> y <code>lsusb</code> son tus amigos ;)
Una vez terminada la configuración guardamos el archivo con el nombre por defecto y salimos del menú. Ahora empezará a compilar nuestro kernel, sus módulos y se generará un initramfs para lanzar con systemd después.
Una vez terminado, y si por algún motivo les aparece una advertencia al finalizar la compilación, recuerden que pueden volver a repetir el proceso. La configuración se almacena por lo que probablemente solo tengan que buscar las opciones que aparezcan con MAYÚSCULA mediante “/” y cambiar los valores por los recomendables. (Este es nuestro paso 15)
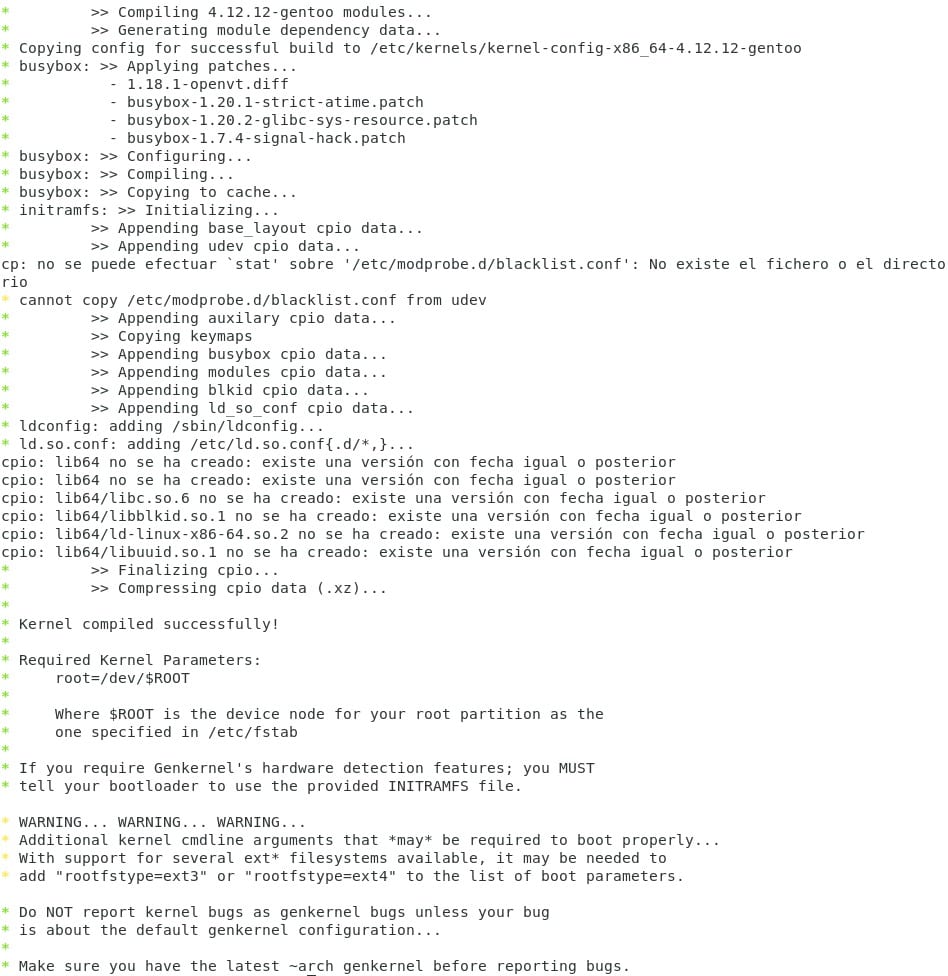
Una vez instalado nuestro nuevo kernel, es hora de decirle a grub que se prepare para correr el sistema. Como pueden ver en la imagen anterior hay un pequeño párrafo de WARNING, nos está informando que nuestro sistema tiene un filesystem distinto de ext2. Esto, y un detalle más, lo vamos a configurar en nuestro grub antes de instalarlo. En el archivo /etc/default/grub hacemos las siguientes modificaciones:
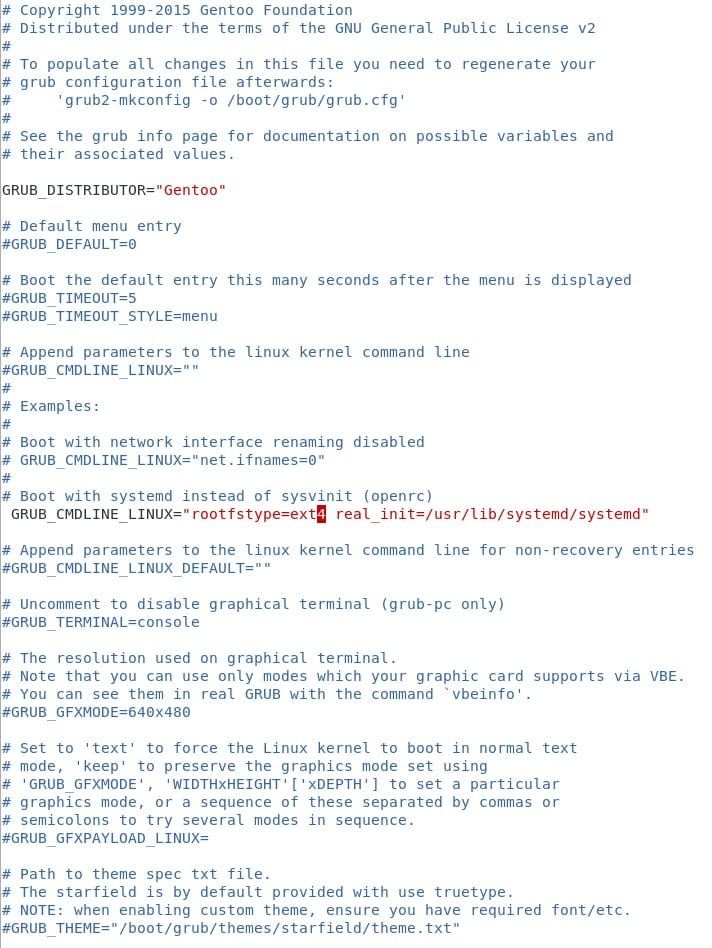
Con esto estamos diciendo a grub que al momento de iniciar el sistema se prepare para usar ext4 en nuestro root ( / ) y que el sistema comience con systemd en lugar de OpenRC. Ahora podemos instalar grub en el disco :) ( pasos 16 y 17 hasta ahora ;) )
Ahora vamos a actualizar el sistema por completo. Esta opción puede tardar cierto tiempo dependiendo del perfil seleccionado y la cantidad de paquetes que necesiten ser recompilados. Como los stage3 son generados cada cierto tiempo, es posible que unos cuantos paquetes necesiten actualizarse en comparación con el resto del equipo ( que debería estar lo más actualizado posible) Para que puedan comprender los comandos que usé tendrán que leer man emerge ;) ¿Pensaron que les dejaría todo totalmente masticado para copiar y pegar? :)
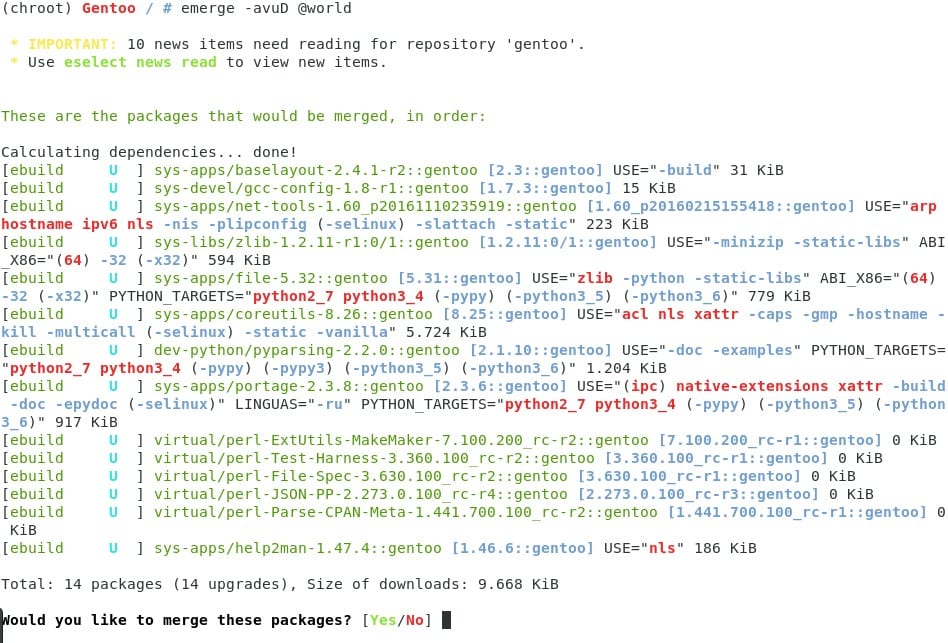
Listo, ya casi estamos en la meta :) ahora solo nos falta nuestro entorno de escritorio, en este caso pueden usar gnome conmigo, o elegir plasma, o el que mejor se les acomode :) Este proceso si va a ser bastante largo, por lo que les recomiendo dejar corriendo la máquina por la noche, así cuando despierten ya podrán empezar a usar su sistema ;) (Paso…18 el anterior y ahora el 19)
Ahora viene el proceso que no voy a poder controlar al 100% y en el que es más que probable que les aparezcan errores. Debido a que el conjunto de paquetes es bastante grande, es posible que existan conflictos con los USE flags, así que les voy a enseñar a resolverlos ;)

Con este comando emerge -av <paquete> estamos pidiendo a portage que calcule todas las dependencias, y probablemente al final obtendremos algo parecido a esto.
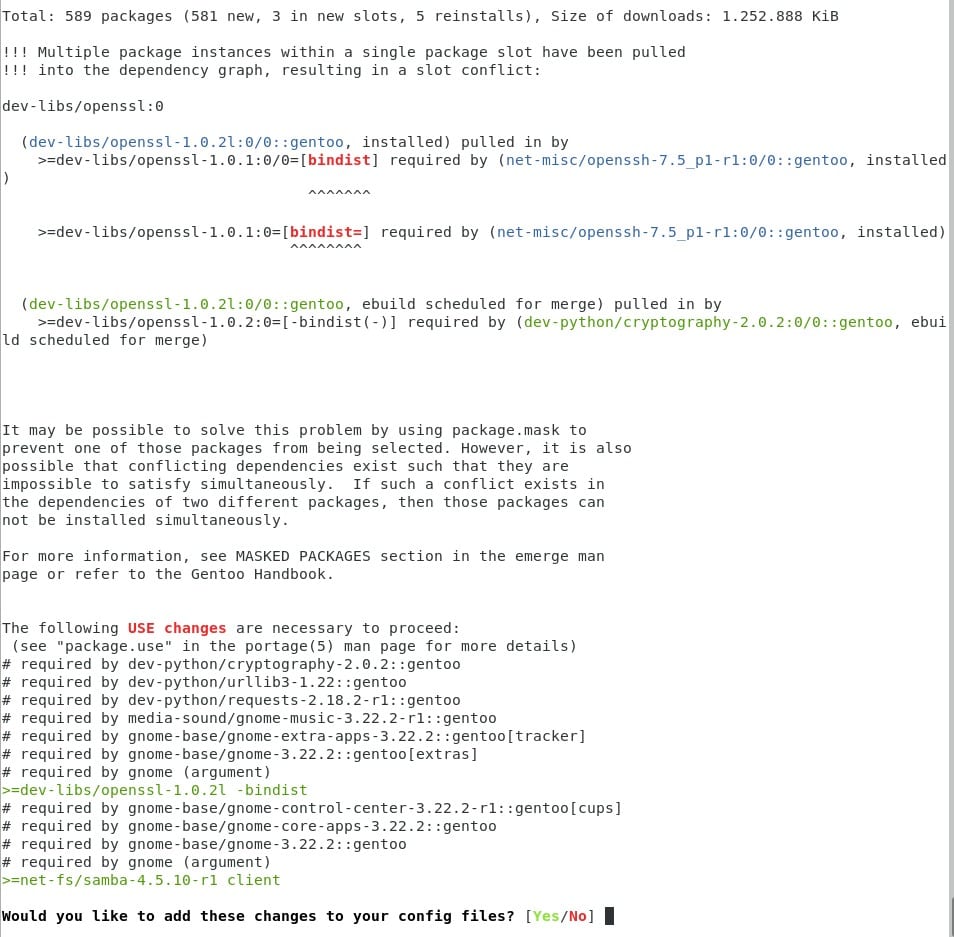
Presionamos No. Para hacerse una idea de lo que acaba de suceder. Nosotros tenemos un stage3 que vino compilado con distintos USE flags, ¿recuerdan?. Ahora que hemos cambiado el perfil, hemos cambiado también los USE flags que venían por defecto. y ahora portage nos está diciendo que existen USE flags que necesita tener para poder compilar la lista de programas que le hemos pedido (en mi caso gnome).
Para resolver estos problemas vamos a crear un archivo con el nombre del programa (para poder encontrarlo después más fácil) dentro de la carpeta /etc/portage/package.use. (Si la carpeta no existe, pueden crearla con el nombre exacto)
Como en mi lista tengo dos, voy a hacerlo de la siguiente manera:

Con esto tenemos todo listo para volver a intentar :) pero antes de eso, solo quiero aclarar que yo pongo el nombre genérico del programa al principio, después los USE flags personalizados, pueden ser 1 o más, el (-) de adelante dice que lo desactive y cualquier línea que comience con # es ignoada por portage. Sencillo ¿no? :) Esta es la magia de la personalización de Gentoo. Pero el trabajo con portage lo voy a dejar para otro post porque este ya está bastante largo :) (Paso 20, troubleshooting :) )
Volvamos a probar el comando de instalación:
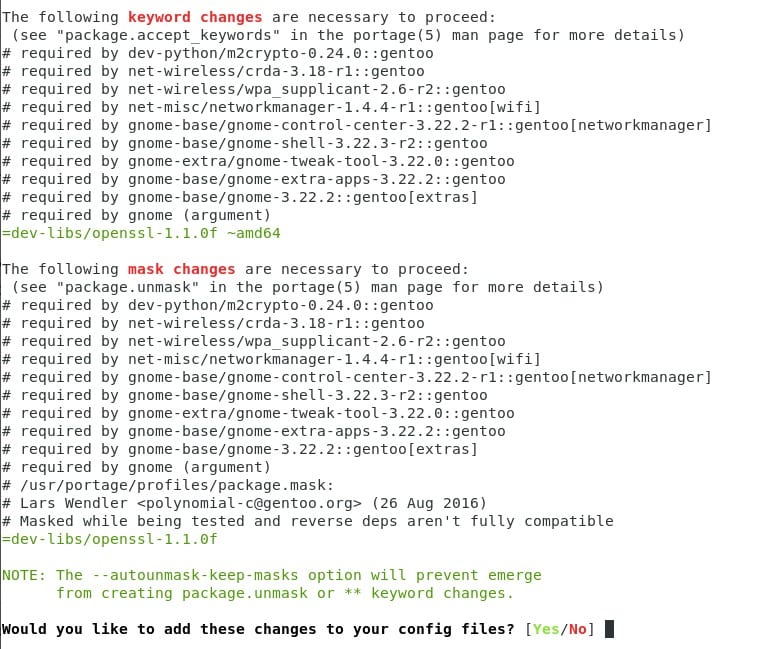
Como es evidente, no hemos acabo bien el paso 20 :P pero ahora estamos frente a 2 errores nuevos que me parecen una estupenda oportunidad para seguir explicando un poco de portage ;)
Los KEYWORD son las etiquetas que tiene un programa que indican qué arquitectura y bajo qué nivel es soportada. En este caso “~amd64″ es la rama “no estable” de amd64. OpenSSL es un programa que siempre viene con una que otra actualización (es muy importante tenerlo actualizado y libre de problemas) así que lo mejor será usar la versión “no estable”. Por defecto los perfiles de laptop soportan “amd64″ o “x86“. Para cambiar esto, es necesario agregar la variable ACCEPT_KEYWORDS=”~amd64″/”~x86″ dentro de make.conf (como dije que voy a mantener simple el post, no lo toco más que esto).
Ahora a lo nuestro, al igual que en el paso anterior, es necesario crear la carpeta package.accept_keywords en /etc/portage y agregar el mismo formato pero con la variable KEYWORD que vamos a usar.

Ya son todos unos expertos en portage ;) ahora vamos a resolver el último problema que hemos visto… cambios de mask. Si son un poco observadores podrán ver lo que les muestro en la imagen y notar que es bastante sencillo.

cabe resaltar que en este archivo, es necesario escribir explícitamente la versión que vamos a usar. En los anteriores es opcional o se puede comenzar con “>=tipo/paquete-versión <variable>” para decir a portage que a partir de esa versión se apliquen los cambios. Volvamos a probar nuestro comando de insalación :)
Nunca me salen tantos errores al momento de instalar pero es estupendo para poder cubrir todo tipo de acontecimiento que les pueda surgir , jajaja :) miremos lo que me apareció:
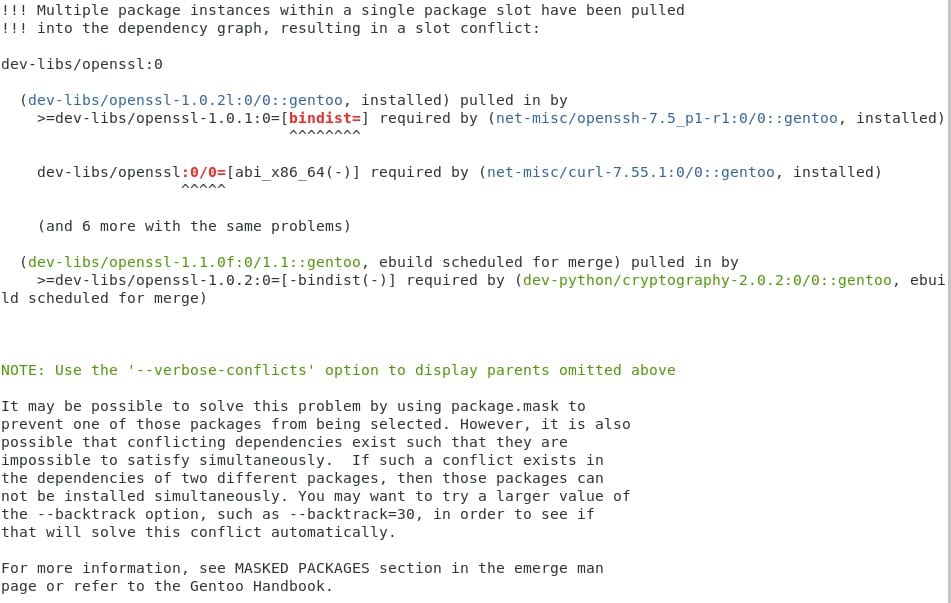
Aquí portage me está diciendo que tengo múltiples versiones del mismo programa y están en conflicto, ¿recuerdan gentoolkit? Lo instalamos junto con el resto de nuestros programas hace poco. Vamos a usar uno de sus comandos eshowkw para ver un poco mejor lo que tenemos ahora.
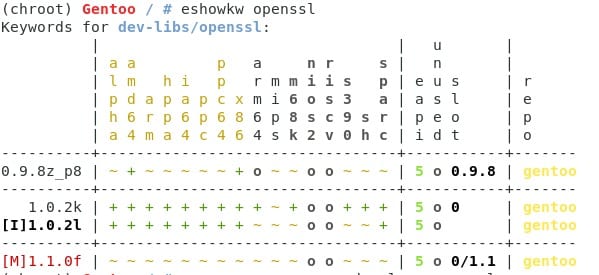
Como podemos ver, ya tenemos una verisón de openssl instalada, el SLOT 0, y nosotros queremos instalar la que tiene la [M] que es es SLOT 0/1.1… el / indica que o es una, o la otra, pero no las dos juntas.
Como vamos a actualizar todos los programas, primero eliminemos el SLOT 0 para poder actualizar de manera sencilla.
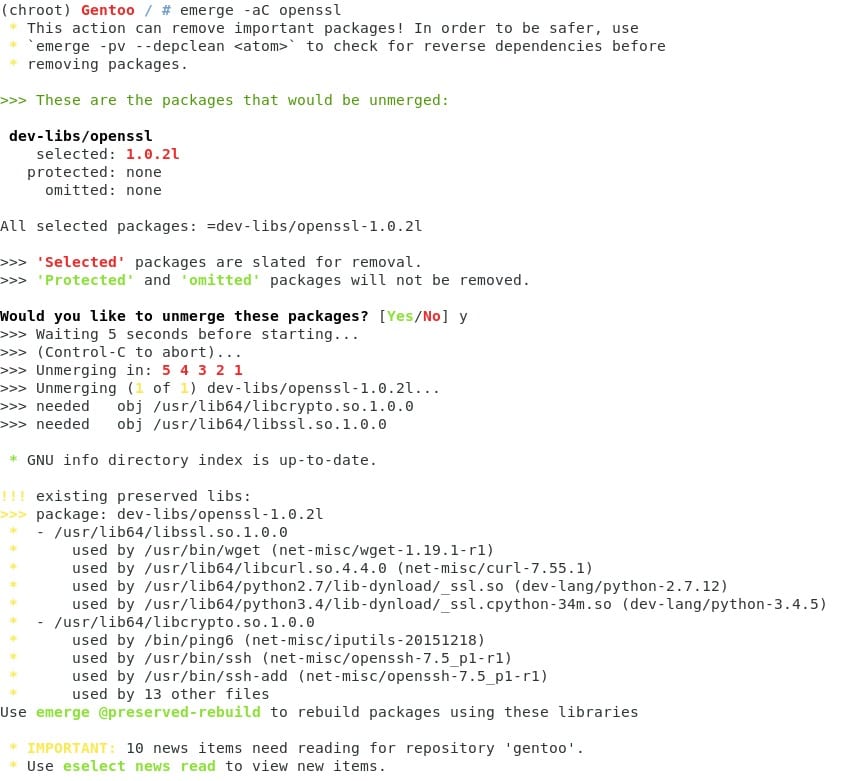
como podemos ver, van a quedar un par de librerías en el sistema porque solo hemos borrado el ejecutable, para eliminar las librerías también debemos usar otro comando, pero por ahora lo vamos a dejar como está ;)
Volvamos a probar nuestro gnome :)

¡Todo listo! Y sin querer también cubrimos un grupo de posibles problemas que podrían enfrentar al momento de instalar :)
Ahora lo dejaremos instalando toda la noche, es bastante como podrán ver, casi 1 Gb de descargas :)
Grub
La instalación de grub es bastante directa grub-install /dev/<dispositivo>
Solo cabe mencionar que deben tener claro que es el dispositivo completo y no una partición. Ponerlo en una partición puede hacer que después no funcione nada. Como en otros lugares, se puede descargar os-prober para poder buscar sistemas operativos en otros discos. El comando que muestro tiene unos cuantos defectos por lo que lo estoy corriendo en un USB y debería ser en un disco duro, pero no deberían salir errores con ustedes.

Ahora, ¿recuerdan el paso configuración de grub de hace poco? pues ahora nos viene a ayudar. Tenemos que crear la configuración de nuestro grub para que arranque con systemd y use ext4 como partición para la raíz.

Listo :) ahora ya tenemos grub configurado y listo para arrancar a la siguiente vez que encendamos el equipo. (Terminamos le paso 21)
El último es simplemente puro detalle :) vamos a activar nuestro servicio para poder entrar en el modo visual a la siguiente. También el servicio de NetworkManager para tener nuestro internet ;)

Disfrutar :)
Bueno, hemos llegado al final y creo que solo me pasé por un paso :P , si no tienes hardware de drivers complicados, si has seguido esto de la mano al Handbook, si has podido resolver tus problemas en el camino… ¡FELICIDADES! Eres de los privilegiados que han experimentado la instalación de Gentoo en su máxima expresión :)
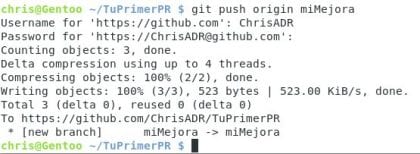
Ahora ya es demasiado lo que he escrito, y seguramente empezarán a surgir detalles que tendré que poner en futuras ediciones del tutorial, pero espero que les ayude a comenzar este proceso de instalación :) Conmigo será hasta la siguiente y con otro post que ayude a disfrutar más de Gentoo y su personalización. Evidentemente también empezaré a escribir otros temas que me apasionan :) Git y el Kernel son proyectos en los que colaboro (hay otros más también) o deseo hacerlo, y si gustan les puedo contar un poco del proceso :)
Saludos,