Es sorprendente la acogida que ha tenido el buen Mar.io y a decir verdad es el primer artículo que publico que genera más de 10 mil vistas, esto pone la valla algo alta para los siguientes y espero no defraudarlos con este :) Muchas gracias por encontrar mis escritos lo suficientemente interesantes como para compartirlos dicho sea de paso :)
Programación
Este es un tema de moda, todo el mundo quiere programar, o al menos todo el mundo piensa que es una habilidad cada vez más necesaria, y a decir verdad a mi me gustaría escribir todo un libro sobre programación, GNU/Linux, seguridad, y tal vez en algún momento lo pueda hacer, apenas aprenda cómo escribir libros libres y en formato agradable :P .
La tecnología avanza rápidamente
Este es uno de los motivos por los que no he escrito el libro todavía :P puesto que quiero hacer algo que pueda superar la barrera del tiempo en un campo en el que las cosas no suelen durar más de unos días de forma vigente. Es por esto que en este artículo quiero contarles un poco de los conceptos más que las implementaciones, de esta manera podremos volver a leer estas líneas en un tiempo y seguirán siendo vigentes.
Los principios se mantienen más tiempo
A pesar de que existen muchos lenguajes de programación hoy por hoy, muchos de los conpceptos se remontan a los mismos orígenes. Con esto quiero decir que muchas de las cosas que hoy se aprenden, han sido válidas por mucho tiempo, y probablemente lo seguirán siendo, esto debido a que la programación es hecha por personas y mientras sigan siendo ellos los que desarrollen, algunos conceptos se mantendrán.
Conociendo las bases
Ya existen muchos cursos, algunos gratuitos y otros no, que exponen gran parte de la sintaxis de muchos de los lenguajes de programación más populares de hoy en día. Pero no vamos a hacer esto aquí :) yo quiero contarles un poco de lo que todo pogramador debería pensar antes de empezar a programar para poder hacer un trabajo decente.
Entrar en la mente del programador es ciertamente algo necesario, ya en un artículo un poco antiguo tratamos el tema. Ahora vamos a entrar un poco en los conceptos que nos permiten escribir el código.
Variables y funciones
Las variables son espacios de memoria, pensemos en los buzones que tienen los grandes edificios, están diseñados para almacenar cierto tipo de objetos, los hay grandes y pequeños, pueden estar solos o en grupo. Una variable es un valor que tu sabes que se usará a lo largo del tiempo, aunque exactamente no conoces su valor en el principio, si lo conoces y sabes que no va a variar, estamos frente a una constante.
Las funciones por otra parte, son conjuntos de instrucciones. Una instrucción es lo más básico que puede hacer un procesador, la razón de ser de las funciones es permitir al programador agrupar conjuntos de ordenes para poder repetirlas a lo largo de un programa. veamos un ejemplo sencillo y a la vez lleno de detalles.

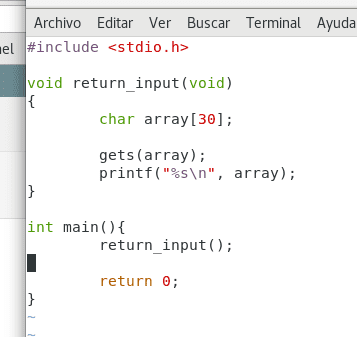
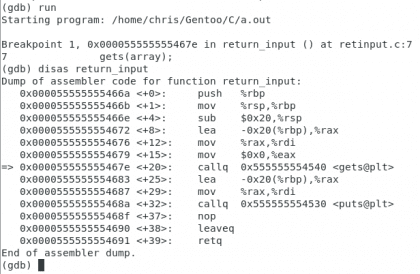
Este es un pequeño programa escrito en C, tenemos la función main, la variable saludo, y la función printf que proviene de la biblioteca stdio.h. Vamos a modificar un poco el ejemplo y luego compilarlo para ver qué sucede.
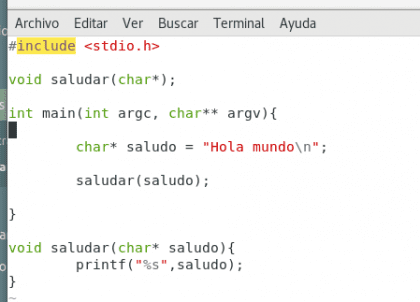
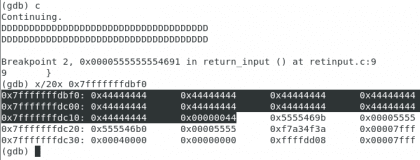
Hemos agregado una pequeña función llamada saludar la cual toma como argumento una variable llamada saludo y la imprime. Esto no cambia mucho el resultado final del programa pero nos permite mostrar un gran y útil principio de la programación, la abstracción. Veamos el resultado:
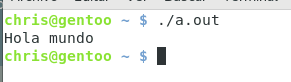
Un simple programa, que está lleno de conocimiento y trabajo.
Bibliotecas
El motivo por el cual creé la función saludar fue simplemente para mostrar uno de los principios más grandes del desarrollo de software, que ya hemos nombrado: la abstracción. Así como hemos definido saludar, printf() ha sido definido en algún lugar de nuestro sistema operativo (la biblioteca standard de C de GNU), este lugar se conoce comúnmente como biblioteca. Las bibliotecas son conjuntos de funciones que nos permiten agregar funcionalidad a nuestros programas sin tener que volver a inventar la rueda. En este caso, gracias a printf no tenemos que preocuparnos de toda la lógica necesaria para poder mostrar en una terminal el mensaje que deseamos.
Las bibliotecas están presentes en casi todos los lenguajes de programación actuales, puesto que al poder contar con secciones de código para elegir e implementar es más sencillo que crear cada función desde cero.
Abstracción
Imaginemos el sistema de correo, nosotros no necesitamos conocer toda la logística necesaria para poder enviar o recibir una carta, lo mismo sucede con la programación, abstraer es esencial para generar código duradero y elegante. Este proceso permite utilizar nombres generales para definir procesos generales. En otras palabras, si creamos la función enviarCarta() sabemos de manera general que dicha función se encargará de enviar una carta, pero no necesariamente qué pasos se requieren para hacerlo. Y este es otro punto por el cual la abstracción es tan buena, puesto que nos permite encapsular segmentos de procesos.
Encapsulamiento
Nuestra función saludar es un claro ejemplo de encapsulamiento, nos permite tener un bloque cerrado con instrucciones específicas que podemos usar una o mil veces dentro de un programa. Esto hace que el código sea más fácil de leer y que sea más fácil de depurar puesto que si algún error surge, sabemos exactamente cuáles son los límites de nuestra función, y conocemos cada instrucción en un espacio reducido. Esto nos lleva a un principio de la programación bastante común en UNIX
Haz una cosa, hazla muy bien
Una buena función es aquella que solamente hace una cosa, pero la hace muy bien. Pensemos en esto por unos instantes… enviarCarta() probablemente haría muchas cosas, lo que no puede ser bueno si queremos depurar el proceso, mientras saludar() solo hace una. A lo largo del tiempo, si surgen problemas la segunda será más fácil de reparar que la primera. Una opción para evitar este problema sería generar distintos niveles de abstracción para enviarCarta(), esto quiere decir que dentro de la función existirían otras como verificarSobre() y tal vez dentro de esta una como verificarRemitente(). En definitiva esta última función (verificarRemitente()) es mucho más específica que solo enviarCarta() y de esta manera podemos encapsular partes del código para que hagan lo que es necesario y solo una cosa a la vez.
Practicar
Para aprender el arte de la programación es necesario practicar, y puesto que yo ahora he dado un vistazo muy general al tema, es necesario que practiquen con diversos lenguajes, o diversos problemas. Primero intentando generar funciones específicas, luego aumentando la complejidad. Como siempre, si surgen dudas, o sugerencias o comentarios, me ayudan mucho a saber qué aspectos reforzar. Muchas gracias y que este 2018 esté lleno de éxitos y proyectos asombrosos. Saludos