Hola a todos :) bastante tiempo sin haber escrito, han sido una locura estos meses, pero este artículo va para un pequeño grupo que formé hace unas semanas, gracias a la aplicación Meetup [1]. Ahora, vamos a comenzar este pequeño artículo contando que me comprometí con ellos a crear el artículo de tal manera que todos puedan contar con sus propios blogs donde colocar su actividad de investigación.
Github
Github es una plataforma para desarrolladores donde puedes almacenar repositorios de código y compartirlos. Muchas empresas y proyectos libres lo utilizan para compartir el código, desarrollar en comunidad y promover la colaboración de usuarios.
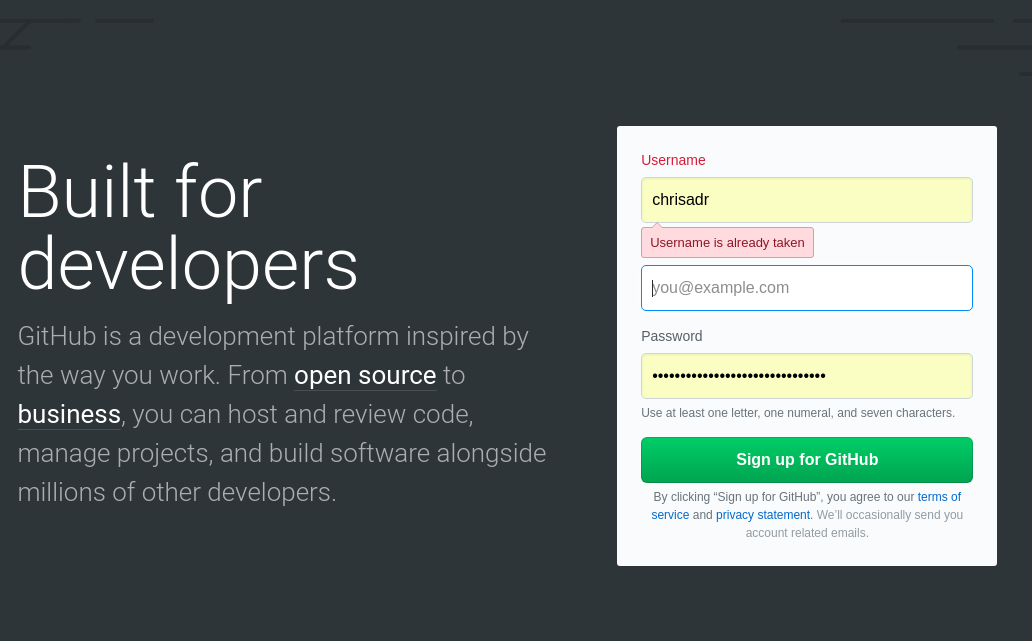
Para crear tu cuenta solo necesitas un correo válido y seguir los pasos de registro:
Una vez tengas un nombre de usuario válido (en mi caso el usuario ya lo estoy usando), vas a poder acceder a tu cuenta.
Creando repositorios
La esencia de Github está en la generación de repositorios basados en la herramienta de control de vesriones Git[2]. Para nuestro objetivo, que es crear un blog, necesitamos crear un repositorio con el siguiente formato:
usuario.github.io
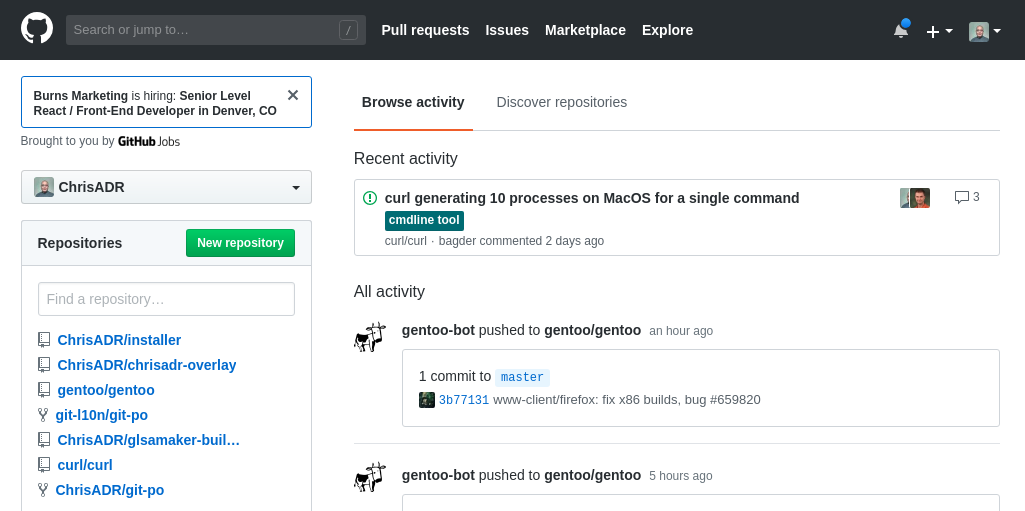
Primero vamos a la opción “New repository” dentro de Github.
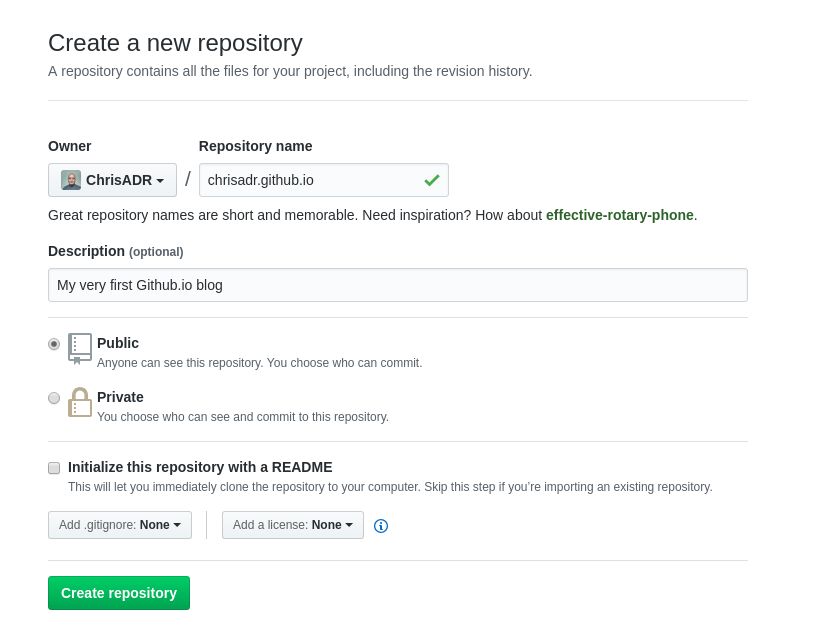
Ahora vamos a llenar algunos datos básicos como una pequeña descripción.
Si todo sale bien, nos llevará a la siguiente página:
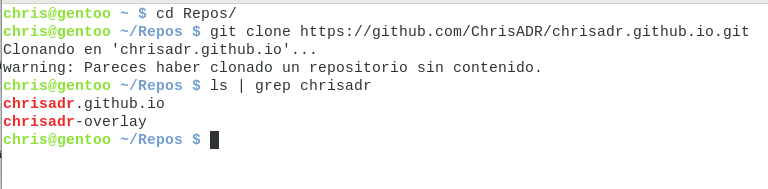
Ahora vamos a tener en cuenta el primer cuadro, que nos dice como llevar nuestro repositorio de la nube a nuestro equipo. Necesitan copiar el link que aparece arriba y en la terminal utilizar git para descargar el repositorio.
Ahora bien, en esas secuencias lo que he hecho es moverme a una carpeta llamada Repos que está en mi directorio personal. Luego clonar el repositorio usando el link, me ha lanzado una alerta porque aparece vacío. Luego mostrarles que se ha creado una carpeta con el nombre de mi repositorio chrisadr.github.io
Formando tu blog
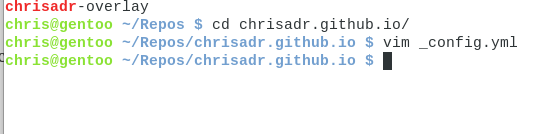
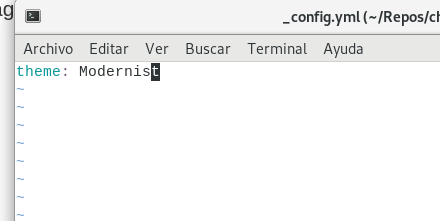
Para poder configurar nuestro blog, solo hace falta crear un pequeño archivo con el nombre _config.yml dentro de nuestra carpeta.
Rápidamente nos movemos a la carpeta del repositorio que hemos creado y vamos a crear el archivo _config.yml con la ayuda de un editor de texto. Yo voy a usar vim pero ustedes pueden usar nano, gedit, o cualquier otro que les parezca mejor.
Para una lista más detallada de todos los temas disponibles pueden ir a [3].
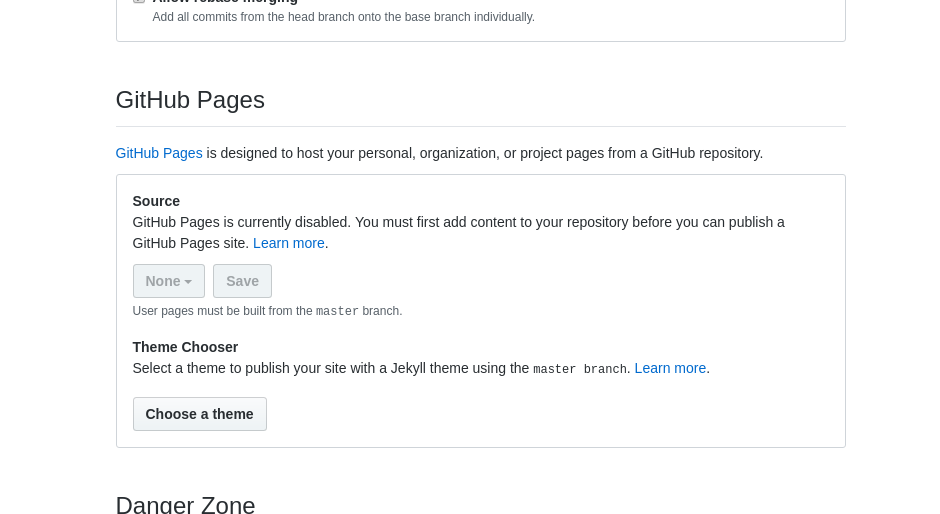
Pero para los que quieren algo más sencillo aún, Github resuelve tus problemas dando la posibilidad de generar el archivo de manera automática. Para esto vamos a Settings > Options > Github Pages
Al dar click al botón Choose a theme los llevará a la siguiente pantalla:
Una vez seleccionado un tema, damos click al botón Select theme.
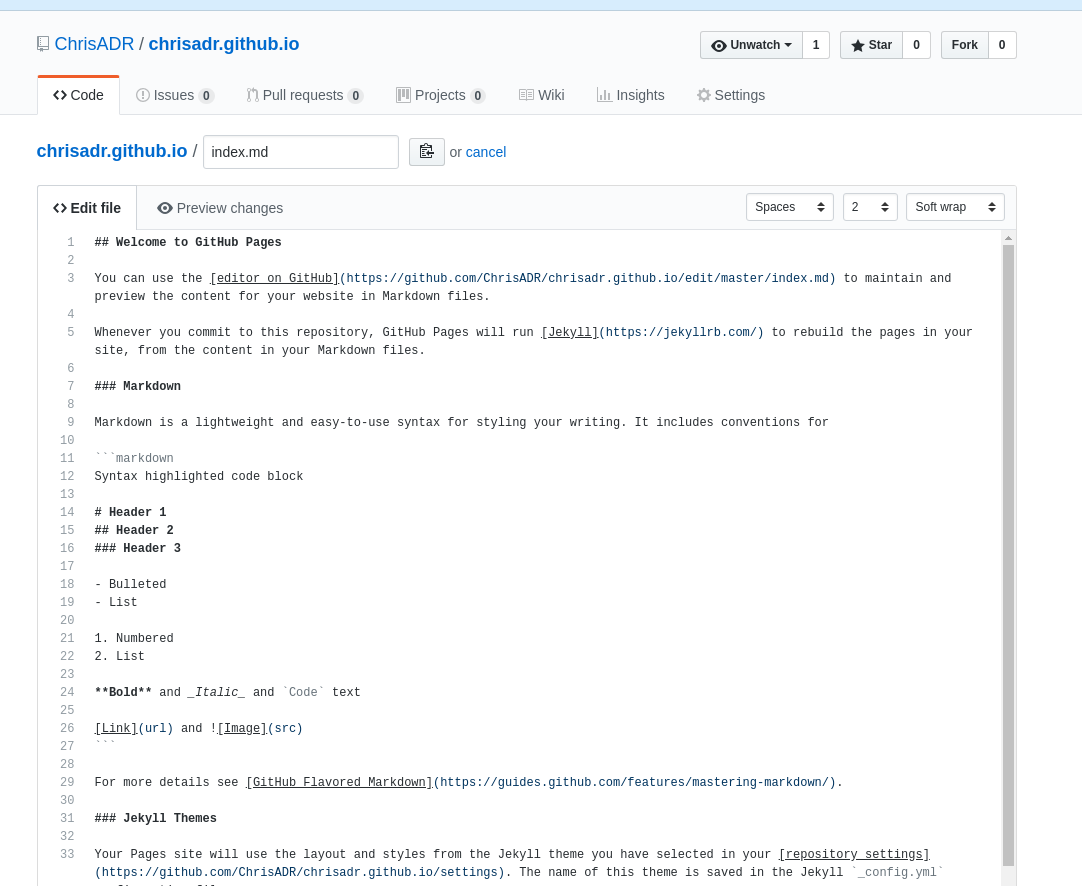
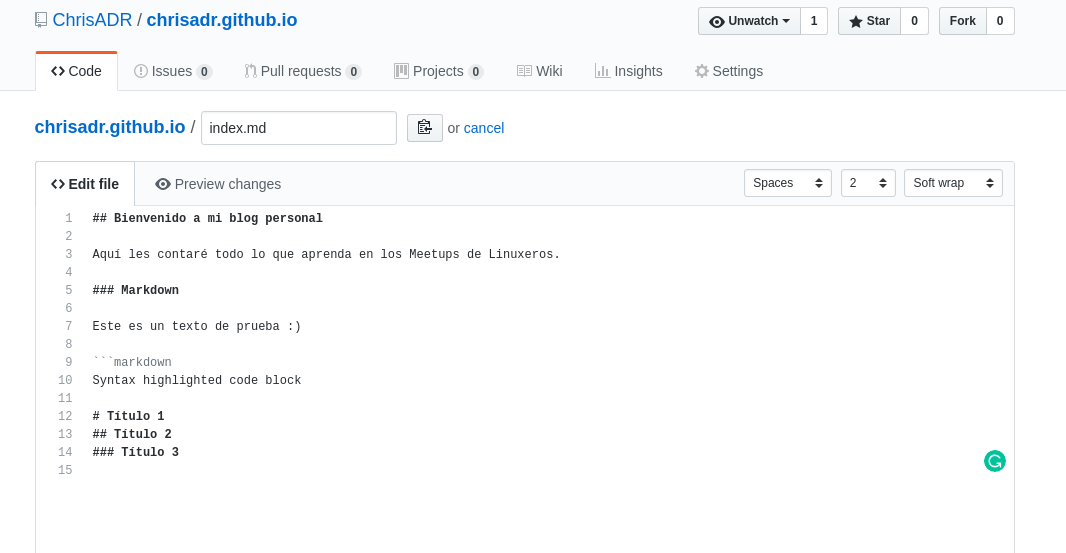
Esto nos llevará a una página de diseño donde podremos ver el index.md de nuestro blog.
Creando tu primer artículo
Como pueden ver, el archivo usa el formato Markdown, que permite generar distintos tipos de letras y formatos mediante códigos como # ## * ** _ etc.
Vamos a crear una página bastante simple para mostrar el index.
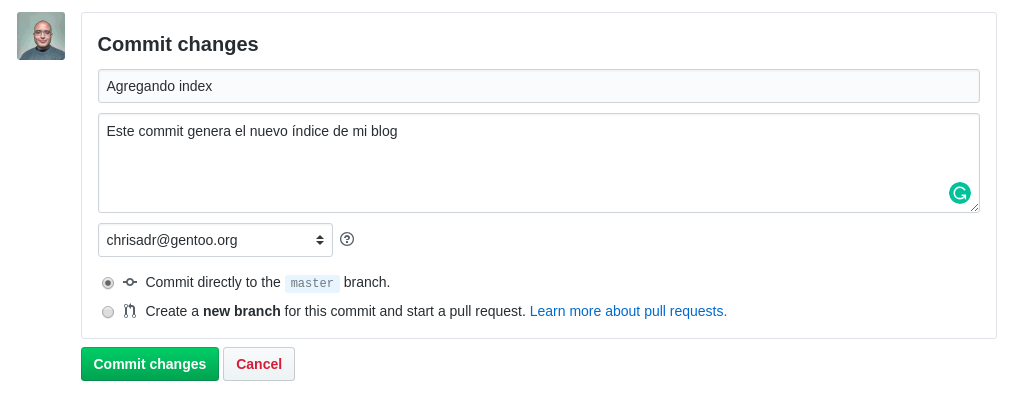
Ahora vamos a ir un poco más abajo en la ventana para guardar nuestros cambios.
Para realizar un cambio, es necesario crear un commit, este debe tener un título y puede llevar una pequeña descripción, luego se le asigna un correo y se puede guardar.
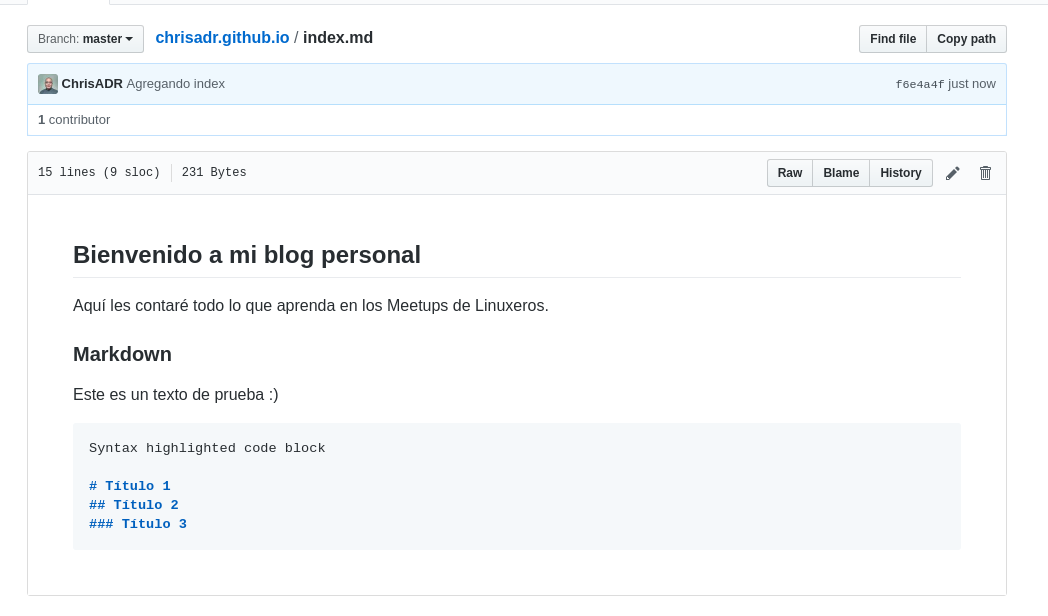
Ahora vamos a ver el resultado en el repositorio:
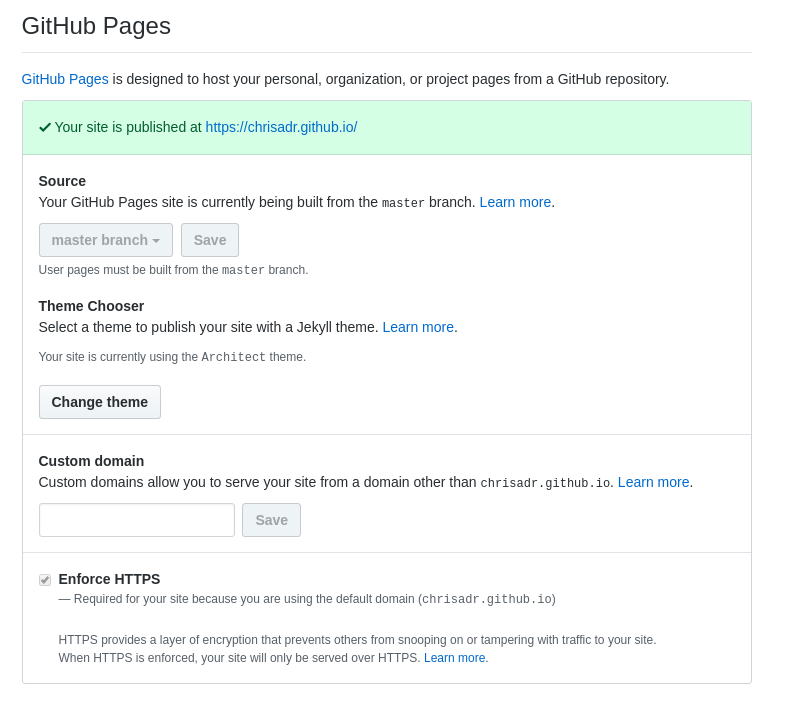
Para poder empezar con la magia, vamos a visitar nuestro link generado automáticamente ;)
Si todo ha salido bien, cuando vayamos a opciones > Github Pages encontraremos el siguiente mensaje:
Damos click a nuestro link generado y voilà:
¡¡Ya tenemos un blog personal!!
¿Ahora que…?
Bueno, ¡este es solo el comienzo!, todavía queda mucho por aprender y como es evidente que esto solo ha sido algo que les permita generar un resultado simple, es necesario leer mucho más, cosas como el formato Markdown, cómo agregar un dominio personalizado, cómo cambiar el título, autor, y estilos, etc etc. Les dejo unos cuantos links que tal vez les den una mano para poder seguir trabajando esto ;) Saludos.
Finally, I’m writing in English, and the best way to begin the internationalization of my posts is to introduce to all of you my tiny project, installer.
What is installer designed for?
installer is a quite simple Python program designed to aid users (especially those who are installing Gentoo for the first time) in the installation process. It is not meant to be a replacement for the Gentoo Handbook, instead, it is designed to work with it and provide a summarized amount of information to the user and if he/she needs more detailed info, the Handbook should be the first point of reference.
Who can use installer?
It requires from users the ability to navigate on a terminal, create partition tables manually, download files, extract, copy or edit them… well being comfortable with the shell in summary. Since the first ACTION available is ‘beginner’, it assumes that the user has never installed Gentoo Linux, but he/she knows enough about how to work to be able to attempt an installation.
Will installer replace the Gentoo Handbook?
Absolutely no. The Gentoo Handbook is the heart from installer, it will point substantial information to users, and especially, it will be the ultimate reference during the installation process, installer only pretends to summarize some of the information and present it in a convenient terminal-size way.
How can I use installer?
Once in the shell, it is as easy as:
installer beginner
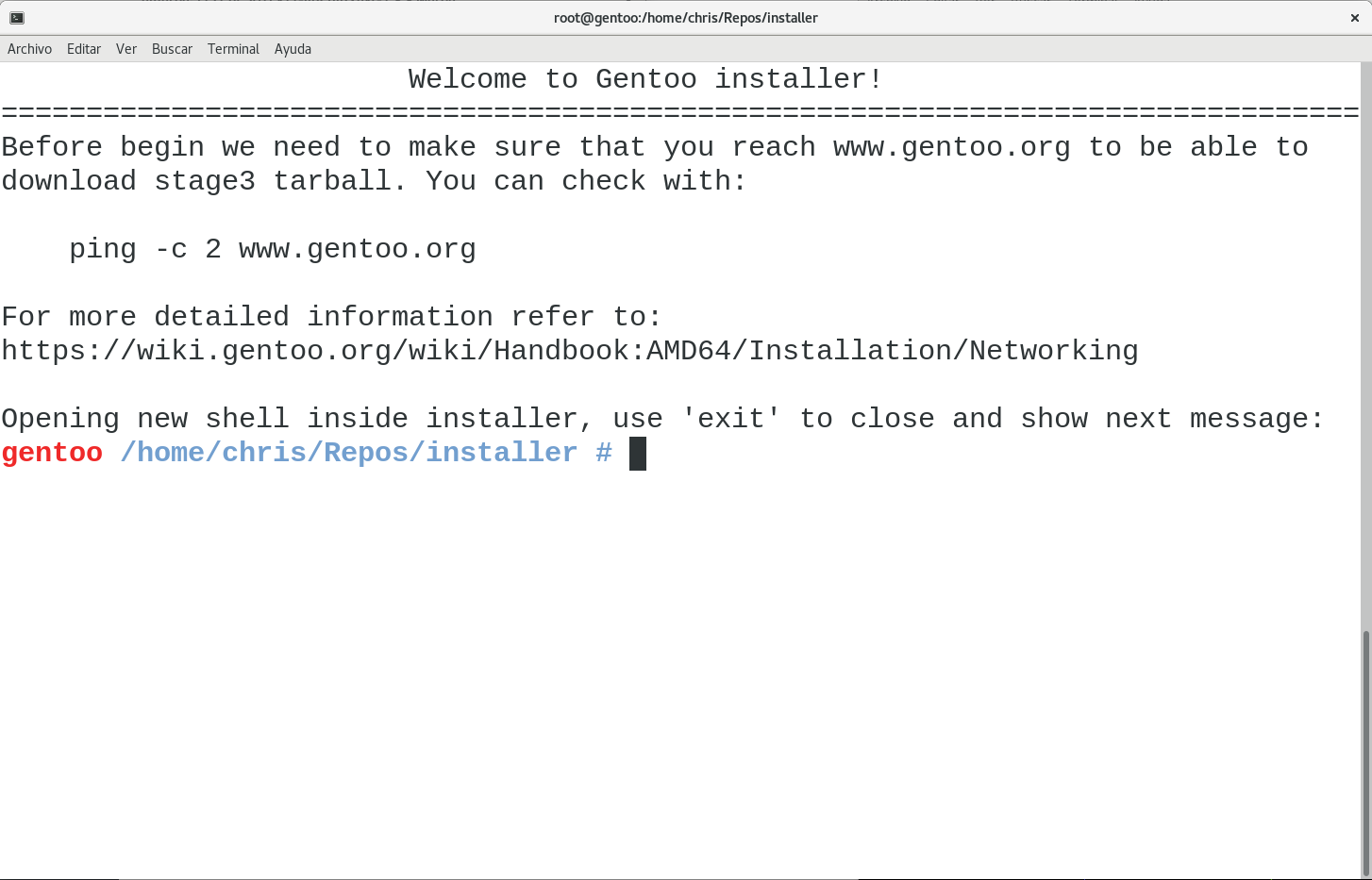
I’ll use my terminal to show you some of the steps required to install Gentoo using installer. This process would be the same as in the Live CD or SystemRescueCD images, the idea is to be able to use installer in both environments and that way begin the normal installation process (I’m working on an ebuild to be able to add installer into both images). As root I’ll execute:
instsaller beginner
And I’ll see the first page:
installer will open a new shell inside where you can write the commands listed above, or any other command that you consider needed to accomplish the task.
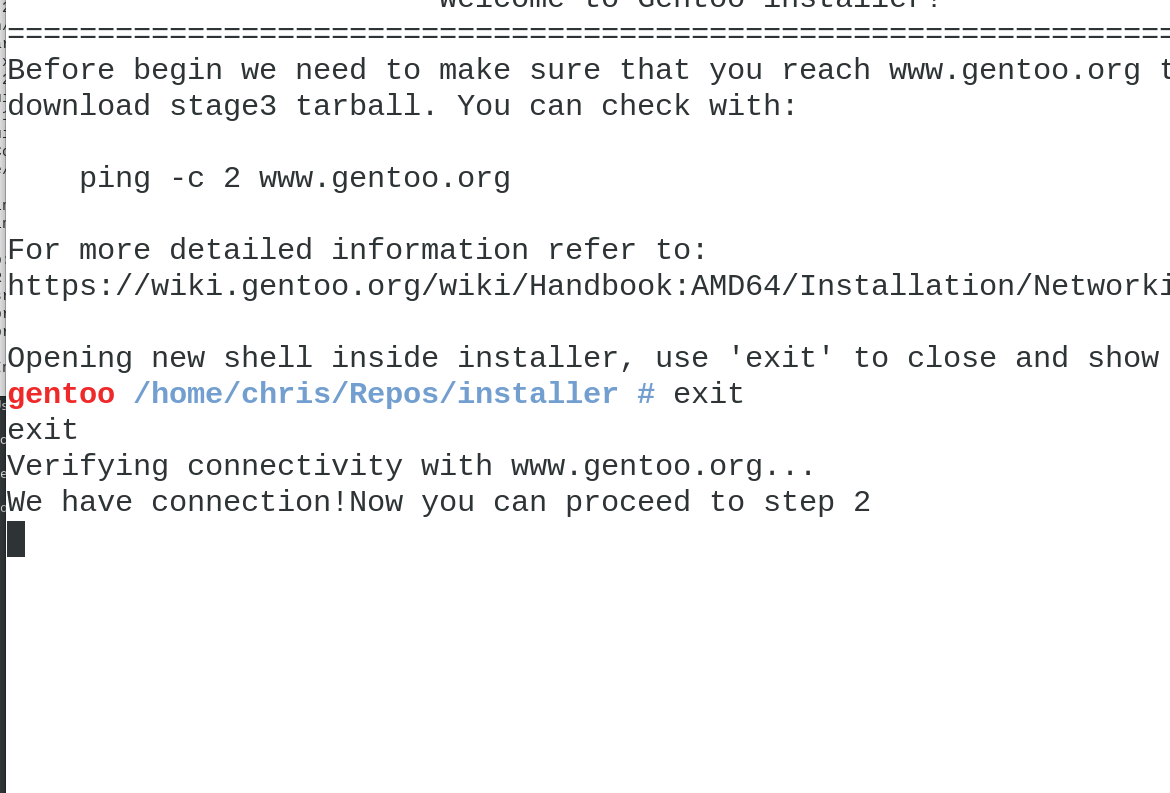
Once you are satisfied with your commands, exiting the shell will show the next message, some steps will validate some information that is absolutely required to accomplish next steps, so let’s write exit and see what happens.
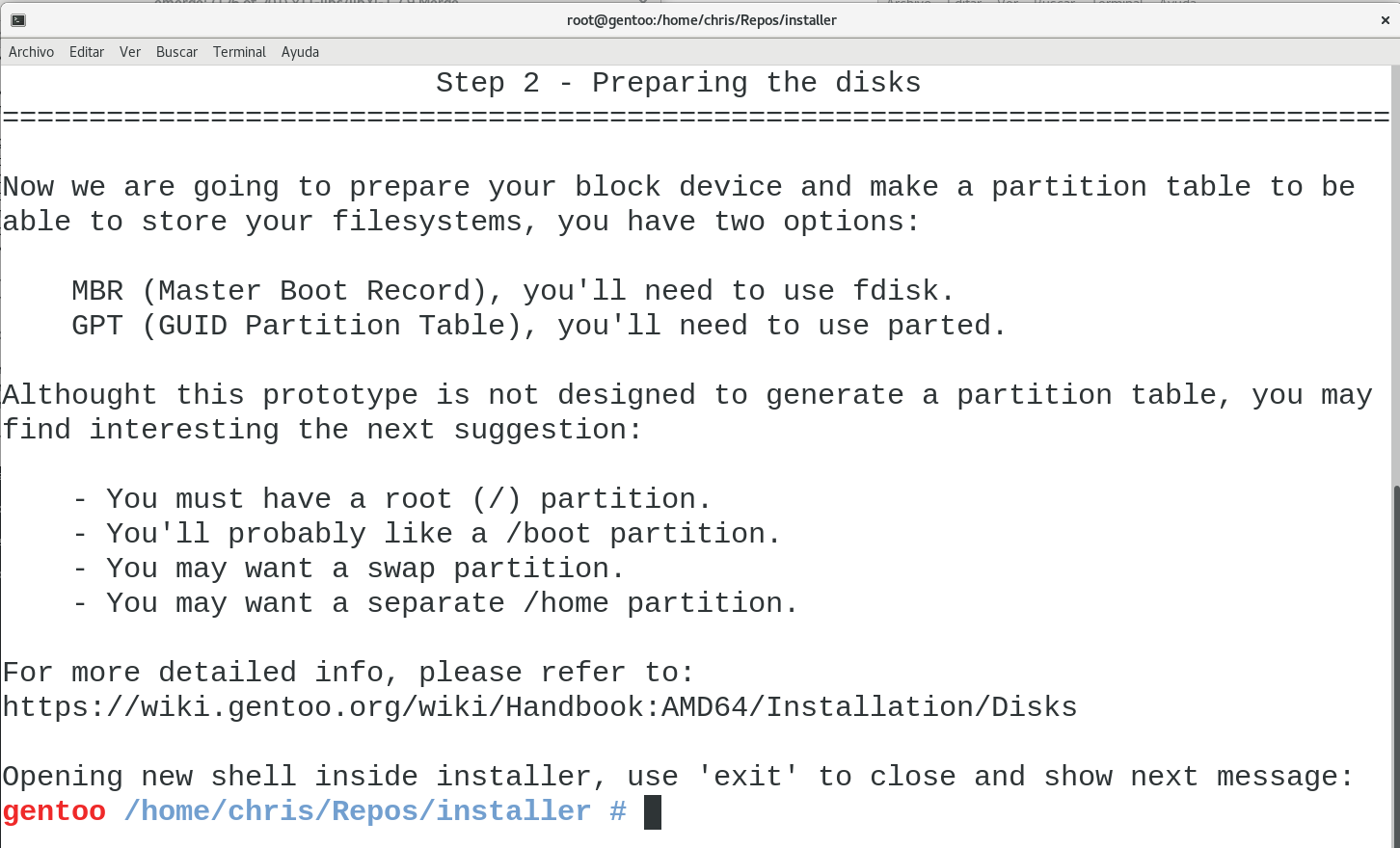
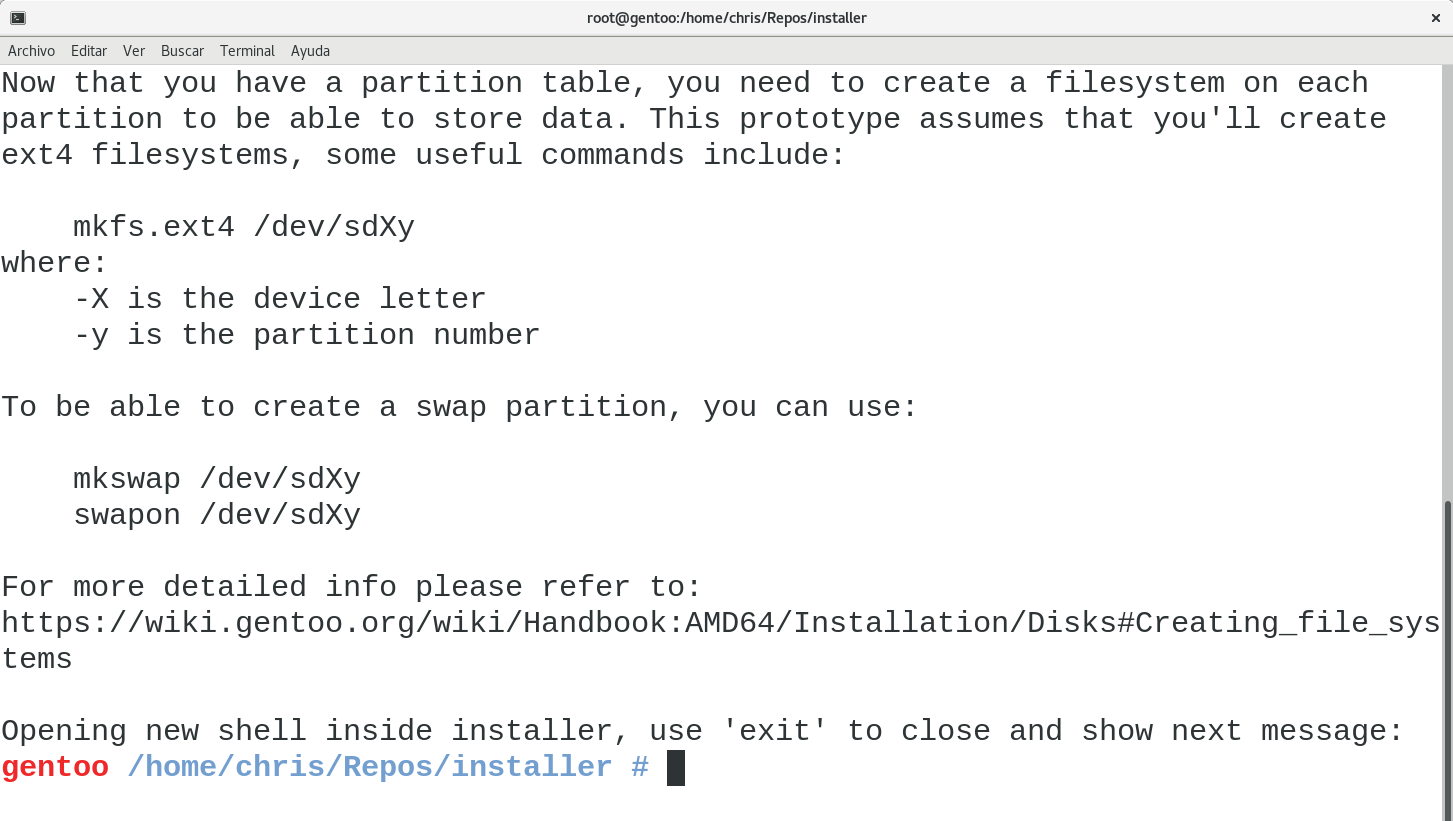
installer does not want to provide the definitive solution to your installation, because of that, it will always suggest what suits for a beginner user, but it’s up to himself to do as installer suggests. Let’s suppose that I only created one big partition for my installation and let’s proceed to the next step.
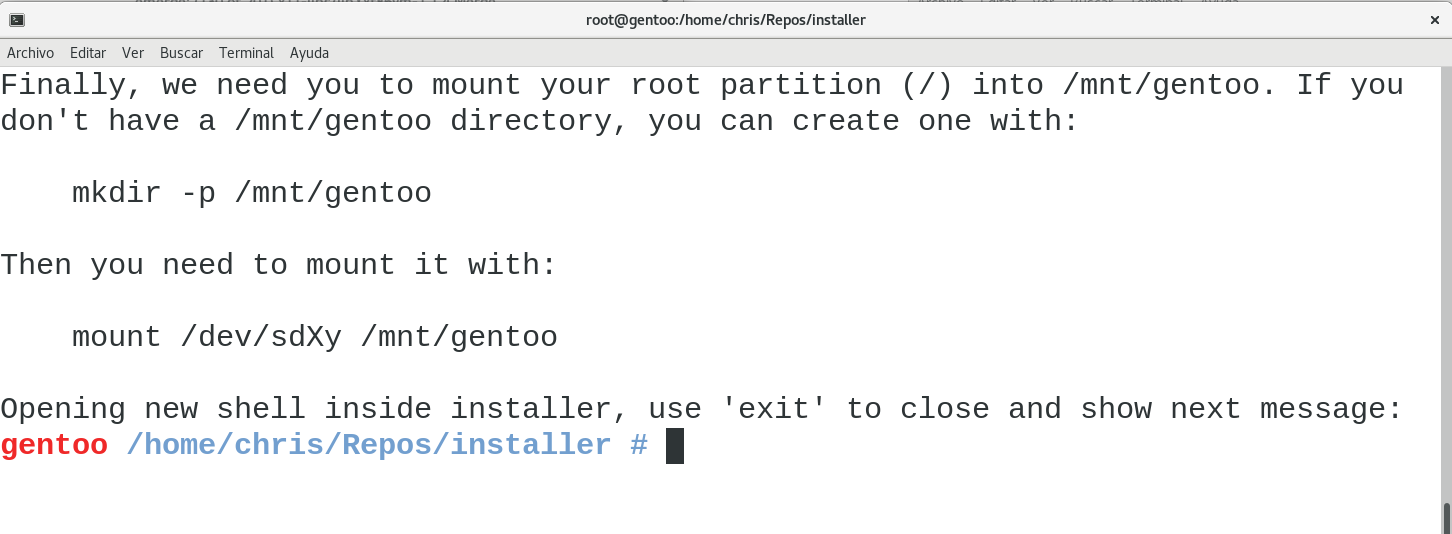
Once again, installer will suggest information to the user, in this case regarding the filesystem, but again, it will be the user’s decision. Let’s see the next step:
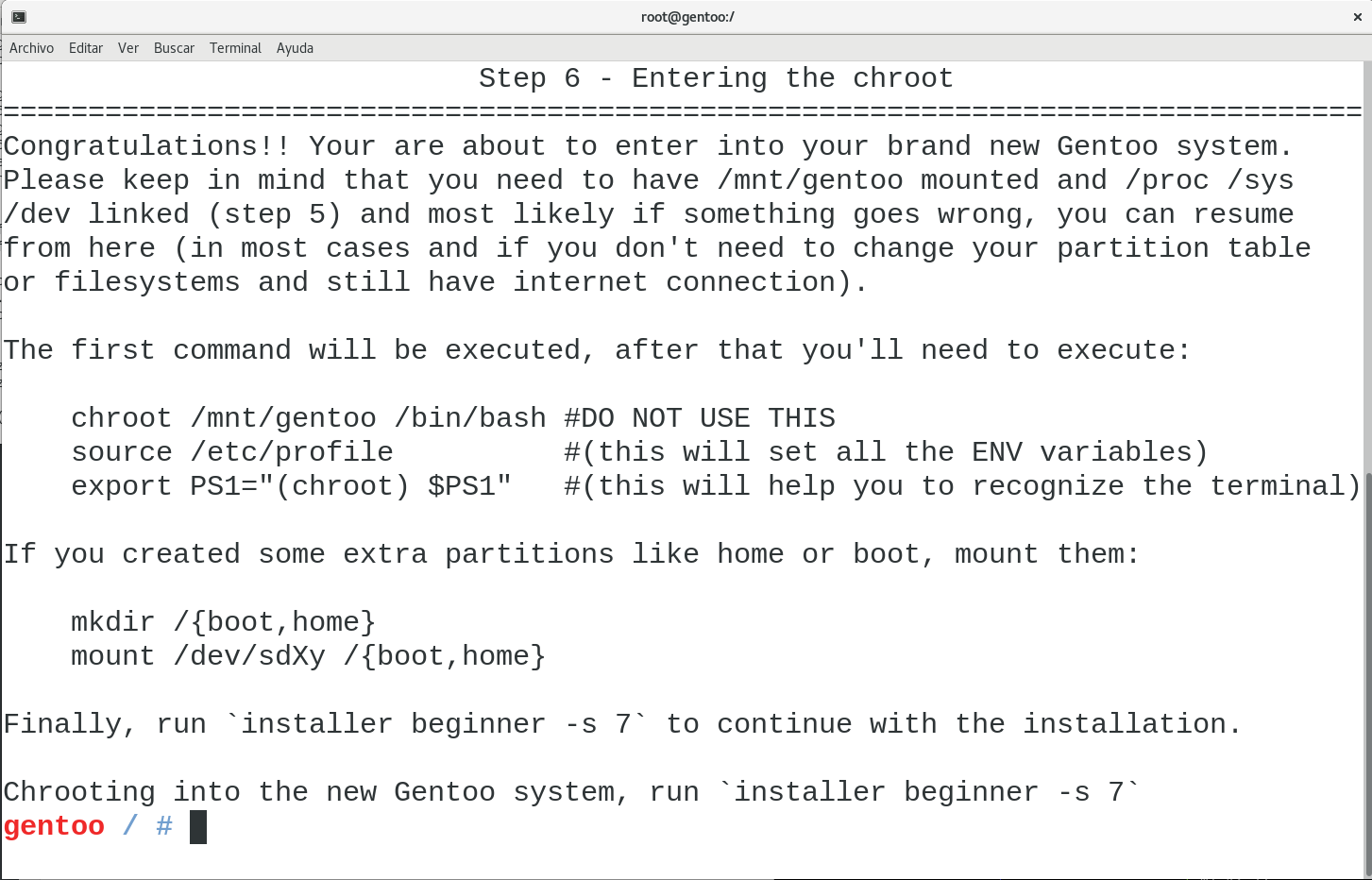
Once mounted, installer will follow the “usual” installation process, meaning that it will assist you downloading the stage3 tarball, extracting it, configuring your make.conf file, updating your ebuild repository and the base system, selecting your profile, entering the chroot, etc.
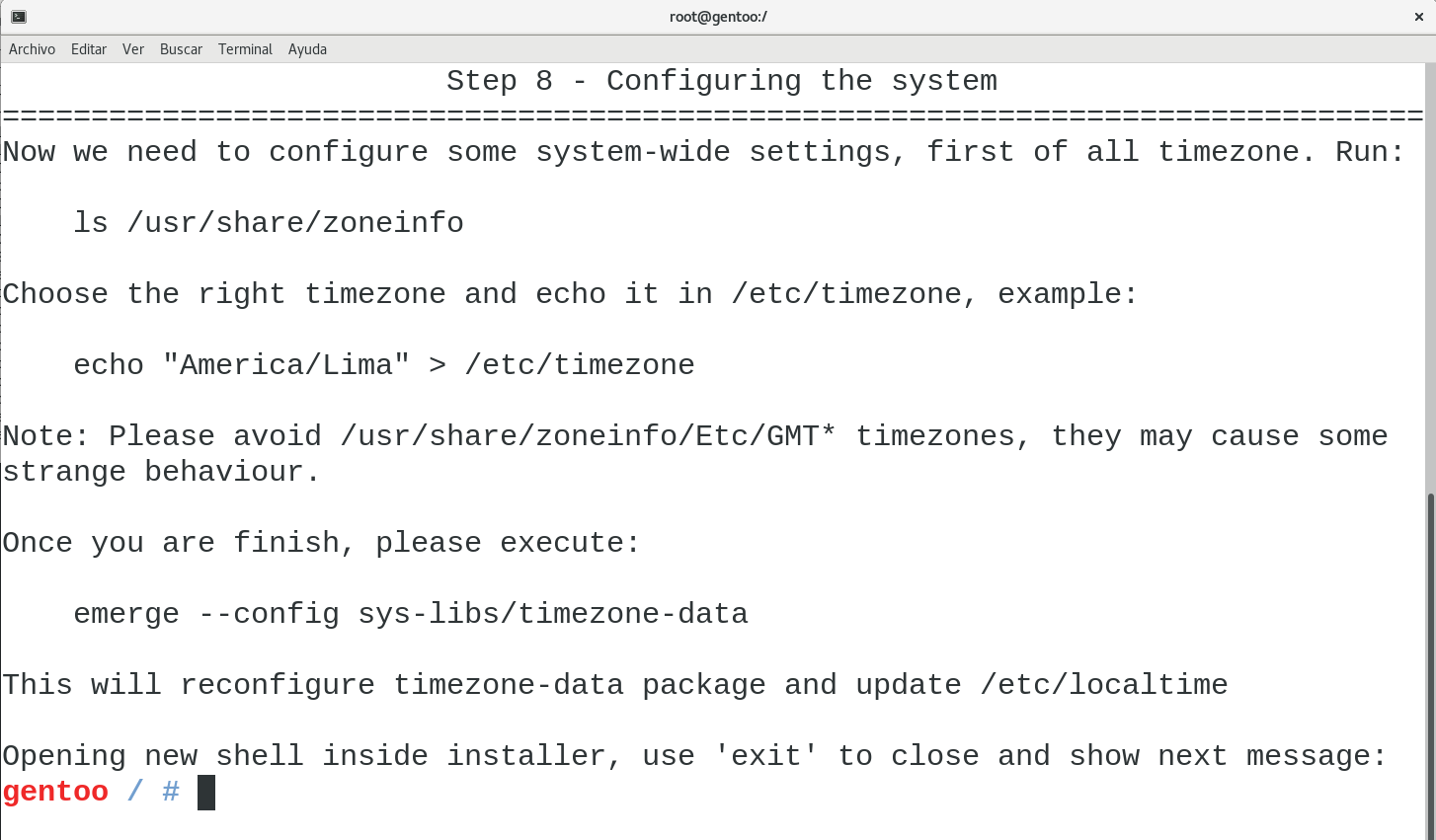
Once inside the chroot, you’ll be able to resume installer and continue with the system configuration, kernel compilation, bootloader installation, among all the other things required to have a working Gentoo box.
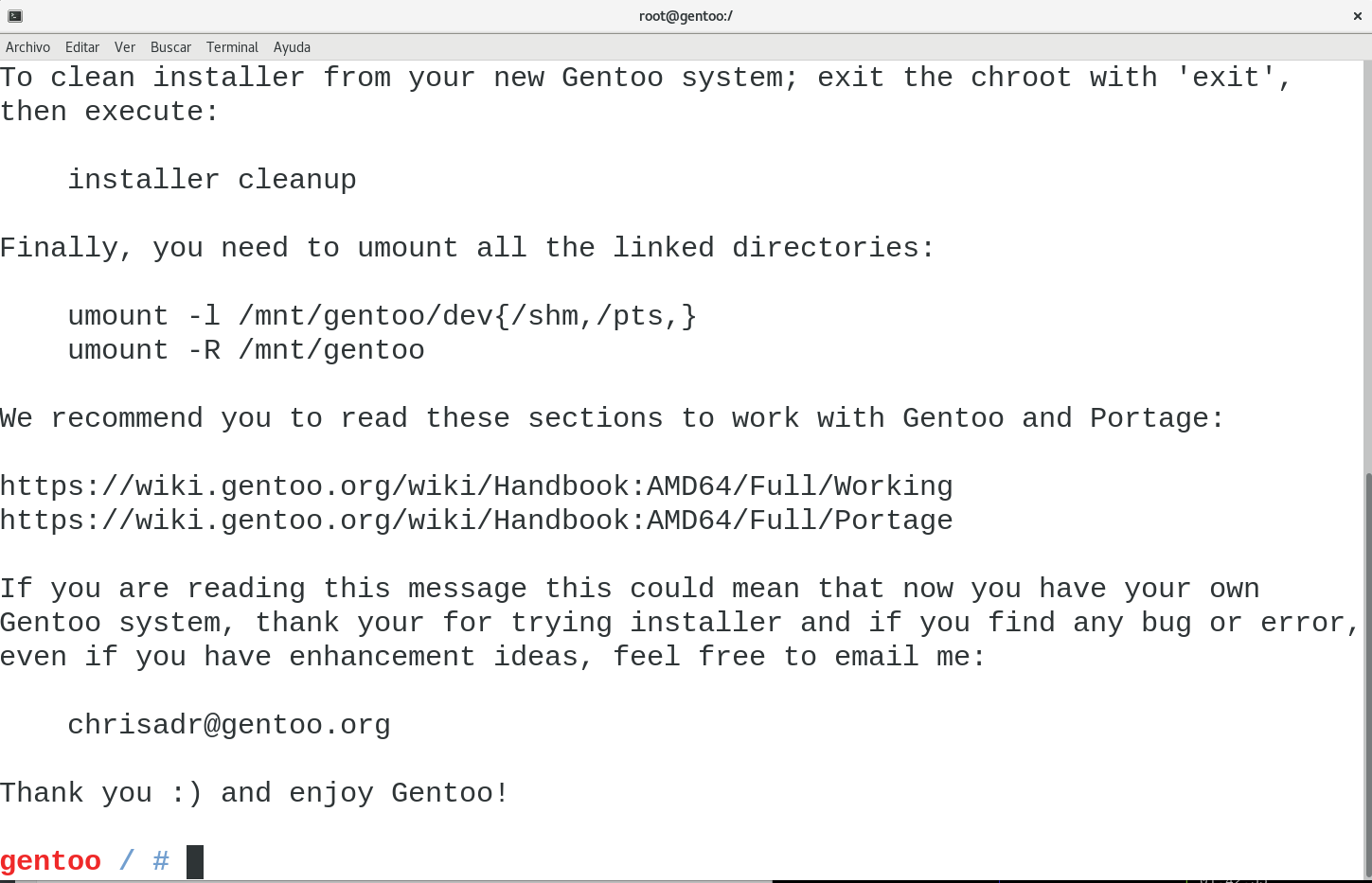
You’ll keep going with all the required steps until you reach the final step, where the user will have to exit the chroot, remove installer from the mounted partition, and reboot in order to start enjoying Gentoo Linux.
What else can installer do?
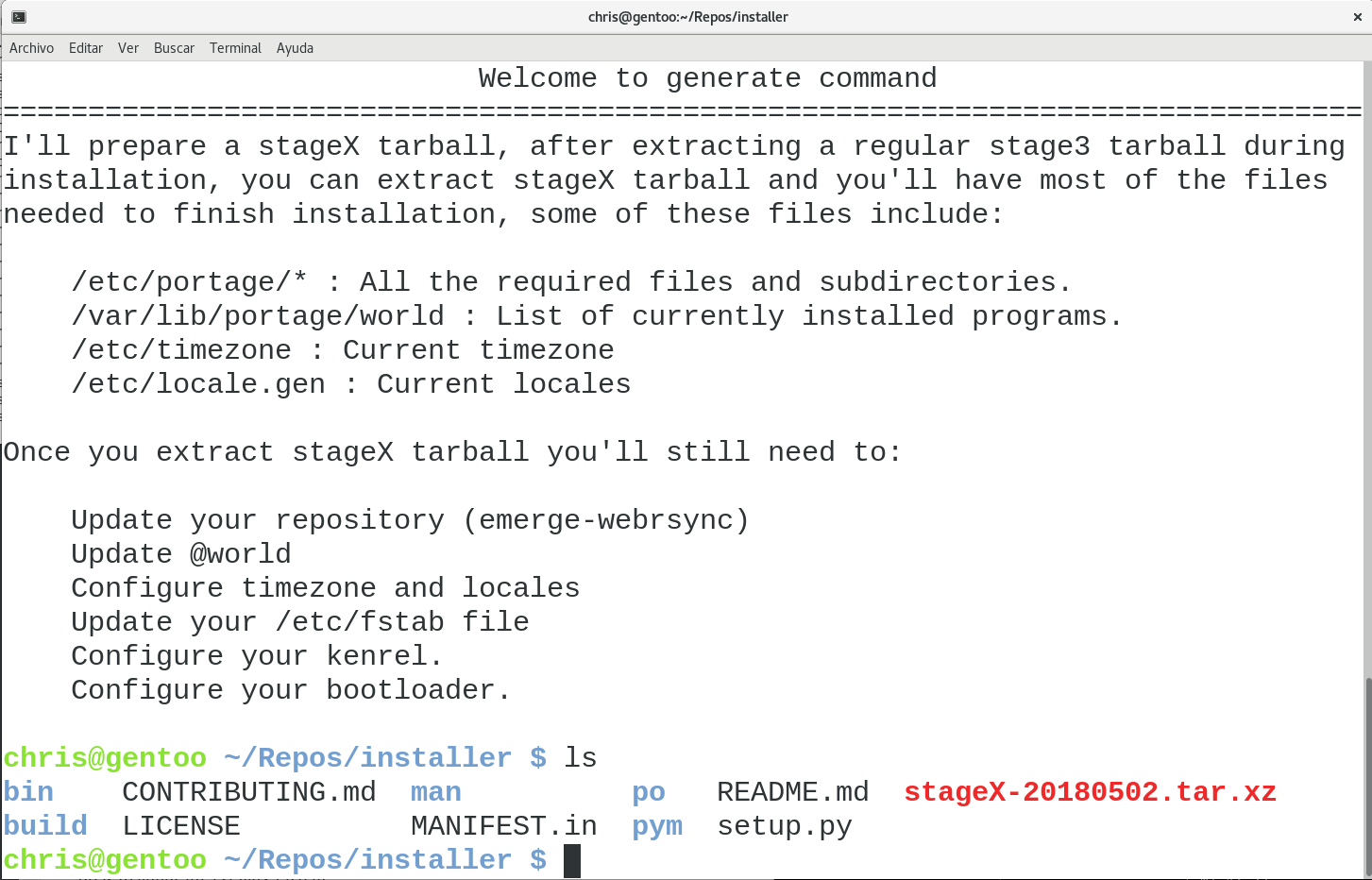
Another action that installer is capable of is stageX generation. A stageX is a tarball that contains most of the configuration required during the installation process. Let’s suppose that I already have a working configuration on my system, and now I want to install the same configuration on a new computer, all I need to do is to generate a stageX tarball with installer generate
Now I can extract a normal stage3 on the new computer, then extract my stageX tarball and I’ll just have to do the last steps from the installation process.
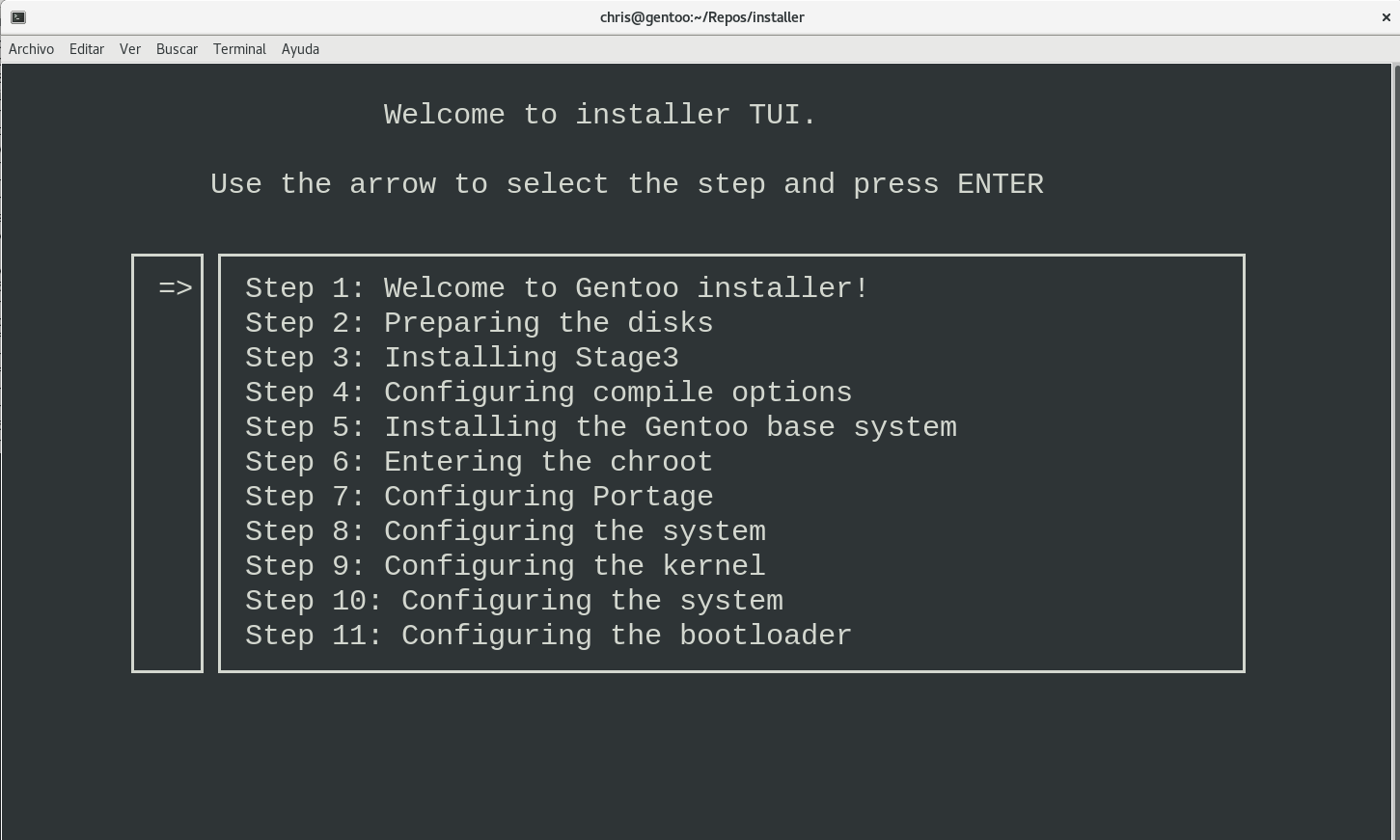
installer‘s Terminal User Interface (TUI)
This is a feature that I’ll still be working on, Gentoo is designed to be as flexible as possible, and each user should be capable of tweak it’s box to the point he/she feels absolute control, when we try to do that with a TUI, the amount of options would be huge, but maybe with some time it’ll be capable of list every possible tweak on an easy to read interface. Right now it helps users to resume from any point of the installation, you only need to execute: installer beginner -t
Final thoughts
If you are here, you pretty much have an idea of my project and thank you for reading this far. If you find it interesting and/or have an idea of a really cool feature, please let me know :) I’ll keep working on the beta for a couple of weeks, installer works right now in English and Spanish, if you want to add another language, let me know and I’ll be more than glad to help you in the translation effort.
Hola con todos :) mucho tiempo desde mi úlitmo post, debo admitir, pero tras poder solucionar unas cuantas situaciones personales y externas, al fin estoy en condiciones de poder escribir nuevamente. Y el primer tema que quiero compartir con ustedes es esta tecnología, que aunque ya bastante tiempo lleva en entornos de producción a nivel mundial, es algo que he descubierto últimamente.
¿Qué es Docker?
Para ponerlo de forma sencilla, Docker es la siguiente generación de virtualización. Esto quiere decir que en su uso, aplicamos las bases de lo que podría considerarse una virtualización ultra ligera. Y esta ligereza radica en su implementación a nivel de kernel.
Docker y el kernel
Antiguamente la virtualización se realizaba a nivel de hardware, esto quiere decir que teníamos sistemas operativos corriendo un kernel especialmente diseñado para generar distintas instancias de máquinas virtuales directamente conectadas con el hardware. Estas soluciones son bastante eficientes y seguras, y permiten una conexión directa cuando hablamos en términos físicos. Con el tiempo se pasó a un modelo de virtualización a nivel de software, donde teníamos un equipo denominado host en el cual se generaba un proceso que producía instancias de máquinas virtuales de tipo guest.
Este es un modelo muy utilizado en equipos personales, al menos yo lo he utilizado durante mucho tiempo y siempre había tenido un tipo de máquina virtual para poder realizar cada trabajo de programación.
Con el paso del tiempo el kernel fue desarrollando nuevas tecnologías que aceleraron el proceso de virtualización, pero también tecnologías alternas que abrieron nuevas puertas.
El overheat
Crear máquinas virtuales no es un proceso sencillo a nivel de recursos, puesto que en las abstracciones necesarias, los equipos tanto host como guest generan todo un árbol de procesos, muchos de los cuales son completamente innecesarios en distintos escenarios, y es este el motivo por el cual en un sistema no siempre puedas tener una gran cantidad de máquinas virtuales, por darles un ejemplo… en mi laptop yo he llegado a ejecutar 4 máquinas virtuales guest en paralelo, pero mi procesador i7 no daba para más, puesto que en todas el trabajo era bastante lento.
Cuando hablábamos de estas nuevas tecnologías, existieron dos que abrieron paso a la era de los containers: cgroups (control groups) y namespaces.
Control groups, namespaces y containers
Los cgroups son una característica del kernel que permite controlar la cantidad de recursos que un proceso ocupa, esto quiere decir que puedo indicar si un proceso tiene un tope de RAM, o de capacidad de entrada y salida, entre otras cosas.
Los namespaces proporcionan contextos de ejecución tanto para usuario como para grupos, en palabras sencillas quiere decir que distintos grupos de procesos pueden contar con un tipo específico de privilegios que no necesariamente aplican para el resto del sistema.
Los containers aplican estas dos tecnologías de la siguiente manera: antes, la virtualización generaba un kernel base, y sobre este se colocaban capas de kernels abstractos o puentes entre host y guest. Ahora el mismo kernel puede manejar todos los procesos, asignando un espacio y una capacidad mínima o máxima. Esto permite que en lugar de la gran cantidad de proceso que una máquina virtual ejecuta, solo se generen 2 o 3 servicios en un espacio aislado.
Imágenes y containers
Las imágenes de Docker son estructuras superpuestas de filesystems que permiten trabajar en la parte superior. Existen imagenes “base” sobre las cuales se van agregando configuraciones y archivos para generar entornos funcionales. Una vez que un entorno funcional se ejecuta, docker genera un container con el proceso que deseemos correr. Esto nos brinda un ambiente aislado donde solo se ejecutan uno o unos cuantos procesos. Esto nos brinda la posibilidad de lanzar cientos o incluso miles de containers dentro del mismo host. Pero como sé que mejor es mostrar que explicar, vamos a ver un ejemplo bastante sencillo :)
Docker y Jenkins
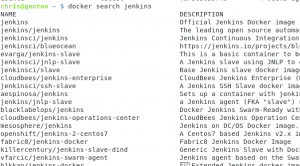
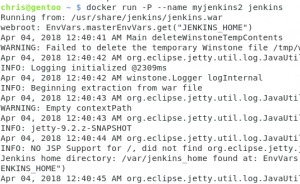
Una vez tengamos el demonio de docker corriendo, vamos a utilizar una de sus principales características, buscar imágenes :) Docker nos brinda un servicio parecido al de Github, en donde podemos descargar imágenes ya diseñadas por otros, en mi caso voy a buscar Jenkins, y como podrán ver, tengo varios resultados. Cuando un nombre no tiene una separación con / se le considera una imágen base. Por lo que vamos a descargar la imagen de jenkins con
docker pull jenkins
Una vez descargado vamos a ejecutar el siguiente comando:
docker run -P --name myjenkins jenkins
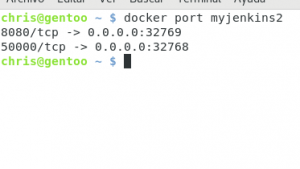
Esto generará una lista de logs que son el proceso de jenkins que se está ejecutando :) ya tenemos un jenkins funcionando, pero necesitamos conocer el puerto en donde está trabajando, para eso utilizamos el siguiente comando:
docker port myjenkins
Como pueden ver, tenemos dos puertos activos, y el conocido 8080 nos redirige a 327669, vamos a abrir ese puerto en nuestro navegador :)
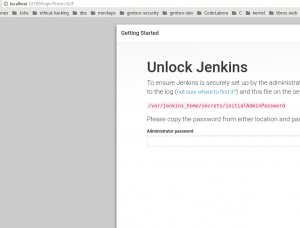
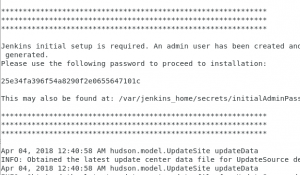
¡Ya casi tenemos todo listo! Ahora nos habla sobre una clave generada, pues sencillo :) en nuestra terminal de logs debe aparecer una clave que podamos usar:
Y eso es todo, ahora tenemos jenkins trabajando en nuestro sistema, pero en su propio container.
Lo genial de todo esto es que ¡tan solo han sido 3 comandos! Y 3 bastante sencillos vale la pena mencionar. Ahora bien, este es solo el principio, pero qué tal si les digera que Docker puede generar redes internas, ambientes de prueba, funcionar como cluster, y muchas otras cosas más… pues ahora entienden por qué tenía ganas de compartir este tema con ustedes :)
Pero son muchos los puntos y un post no alcanza para poder contarlo todo, así que tal vez con un poco de tiempo podramos seguir este tema si lo han encontrado interesante :) Un saludo y gracias por su visita. Ahh y lo olvidaba, para detener el container y volverlo a encender en otro momento pueden usar:
Saludos a todos :) Este post se mantendrá corto pero espero que sea de utilidad a más de uno, y encienda la curiosidad de muchos al mismo tiempo. Cuando hablamos de programación, muchas veces encontrar un trabajo que se ajuste a tus deseos y expectativas es bastante complicado. En especial si vives en regiones como las nuestras donde la demanda no siempre va en la dirección en la que uno se desarrolla.
Pero esto no solamente es complicado para aquel que busca un trabajo, sino que lo es también para aquellos que requieren trabajadores, las organizaciones luchan por encontrar el mejor talento posible, y muchas veces les es complicado por falta de presupuesto o impacto o cualquier otro factor externo.
Es por esto que el gigante de la tecnología lleva más de 10 años trabajando de manera constante para conectar desarrolladores prometedores y vincularlos con proyectos que hacen la diferencia a nivel mundial. Entre las muchas organizaciones que participan en este proyecto, todas sin excepción desarrollan tecnologías abiertas o libres, y el campo de acción de cada una puede ir desde los automóviles inteligentes, pasando por el desarrollo de páginas web, o incluso llegar a temas no relacionados con la programación como pueden ser la revisión de licencias, documentación, traducción, diseño gráfico, organización de eventos, etc.
Cómo funciona
El Google Summer of Code (GSoC) es un evento que se lleva a cabo durante el verano del emisferio norte, (~mayo – ~agosto), en el cual los participantes seleccionados trabajan a tiempo completo (40 horas semanales) de manera remota, con una organización específica. El proceso de selección de las organizaciones comienza en enero, y la resolución de las organizaciones seleccionadas suele aparecer a mediados de febrero.
Cuando una organización es seleccionada, esta cuenta con una lista de proyectos por los cuales Google se ofrece a pagar al estudiante para completar en el plazo de los tres meses. Es un proceso en el cual se cuenta con la ayuda de un mentor, y se llevan reuniones semanales de seguimiento para poder corroborar los avances y problemas que puedan surgir en el camino.
Las inscripciones de estudiantes pueden iniciar en marzo, y entre marzo y mayo existe un periodo de probación y selección donde tanto las organizaciones como Google eligen a sus participantes para la temporada.
Los estudiantes
La definición de estudiante aplica tanto para jóvenes que busquen su título profesional, como para personas llevando títulos de maestrías, o incluso doctorados, la única condición es cursar estudios en alguna universidad acreditada en el momento de la selección para la participación en el GSoC. Además es necesario ser mayor de edad (18 años). Los estudiantes deben acordar un reglamento de comportamiento, que en palabras sencillas significaría, se amable con todos, estudiantes/mentores/colegas, y todo va a ir bien.
Los proyectos
Existe una lista completa de proyectos que se pueden revisar, y dentro de ellos encontramos organizaciones como Gentoo, GNU, The Linux Foundation, Apache, GNOME, KDE, Python, etc etc. Cada una de estas cuenta con una lista propia de proyectos, pero si uno desea, puede presentar un proyecto personal, los requisitos para el proyecto son simples: contar con un horario bien definido (tareas, subtareas, tiempos) y presentar por qué sería bueno completar dicho proyecto para dicha comunidad.
Para una visión más específica de cada proyecto, es necesario ver detalladamente cada página personal, y eso es algo que me tomaría mucho aquí por ser tantas las organizaciones, así que les voy a contar un poco de lo que yo estoy haciendo y el motivo por el que les estoy contando sobre el GSoC :)
The Linux Foundation
No es un secreto para nadie que yo ya he tenido contacto con esta organización, hace unos meses me pude certificar como SysAdmin gracias a sus cursos y hoy estoy en rumbo a poder participar en su GSoC. El proyecto en el cual estoy intentando clasificar es el desarrollo de un driver para un sensor multipropósito de BOSCH, el cual sería integrado en el kernel 4.16.x o 4.17.x en caso de que el proyecto tome más de lo esperado.
Ahora seguro más de uno se preguntará qué tanto sé yo sobre drivers, y la respuesta es simple, no sé casi nada :) pero esto es lo maravilloso de los GSoC, que existen comunidades siempre dispuestas a poder guiarte en el camino de aprendizaje, y en este camino pues estoy aprendiendo mientras descubro un poco de las bases del desarrollo de drivers, esto debido a que en un correo con el Dr. Stallman hace unos meses, me comprometí a en algún momento de mi vida, desarrollar un driver para mi tarjeta de wifi, la cual es el único blob privativo que tengo que usar en mi laptop para poder contar con conexión a internet por WiFi.
Bueno, en mi grupo nos han presentado una pequeña lista de tareas, las cuales debo cumplir antes de poder aplicar oficialmente al Google Summer of Code, entre las cuales tengo cosas como mandar parches a un subsistema del kernel en específico, intentar migrar drivers de la zona de “pruebas” al árbol principal, y una que otra tarea más.
En estas cortas semanas he conocido más estudiantes que están buscando participar, uno de ellos estudiante de master de Brasil, otro estudiante de ciencias de la computación en Europa, ciertamente personas muy capaces que también están en el camino de aprender como yo :)
Para participar
Para participar no necesariamente debes ser un experto programador, a menos que tu proyecto lo requiera, pero sí es necesario que seas capaz de comunicarte de manera virtual con la comunidad, muchas veces esto será en inglés, a menos que encuentres un miembro que domine otro idioma. Más de uno estará renegando al leer esto, pero tenemos que enfrentar el hecho de que si las comunidades tuvieran más miembros de habla hispana (nosotros) seríamos nosotros también los que podríamos participar en esas organizaciones como mentores para ayudar a jóvenes a integrarse en la comunidad.
Como sé que deben estar con muchas preguntas que yo no puedo responder ahora por tiempo o por falta de creatividad, les dejo el link oficial del GSoC para que puedan ver todo el proceso a detalle aquí.
Saludos y espero que más de uno se anime a participar :) tal vez uno que otro quiera entrar a ayudar en Gentoo, eso sería genial también ;)
Saludos a todos :) estas semanas he estado bastante entretenido leyendo algunos libros sobre programación, la verdad es que la mejor forma de aprender a programar es siempre con un libro, cualquier artículo, tutorial, guía que uno pueda encontrar (incluyendo las mías) son meros puntos de referencia al momento de compararlas con un libro de verdad sobre el tema. Ahora bien, tenemos que definir lo que es un libro “de verdad” también, puesto que no todos los libros suelen ser buenos, y muchos de ellos pueden incluso costar más de lo que realmente valen y hacernos perder tiempo.
A lo largo de estos años la lista de libros que he leído y la de libros que puedo recomendar han divergido bastante, pero sin lugar a dudas entre algunos de mis favoritos tenemos (en ningún orden específico):
CEH Certified Ethical Hacker de Matt Walker.
Beginning Python: From Novice to Professional de Magnus Lie Hetland.
Hacking: the art of exploitation de Jon Erickson.
Getting Started with Arduino de Massimo Banzi.
Learning the bash Shell de Cameron Newbam & Bill Rosenblatt.
Learning the vi and vim editors de Arnold Robbins, Elbert Hannah & Linda Lamb.
Linux Kernel in a Nutshell de Greg Kroah-Hartman (un developer de Gentoo también).
Modern C de Jens Gustedt
The Shellcoder’s Handbook de Chris Anley, John Heasman, Felix “FX” Linder & Gerardo Richarte.
The C programming language de Brian W. Kernighan & Dennis M. Ritchie (creadores de C)
Debugging with GDB de Richard Stallman, Roland Pesch, Stan Shebs, et al.
Hacking Linux Exposed: Linux Security Secrets and Solutions de un gran grupo de investigadores de ISECOM, entre ellos Pete Herzog, Marga Barceló, Rick Tucker, Andrea Barisani (otro ex developer de Gentoo), Thomas Bader, Simon Biles, Colby Clark, Raoul Chiesa, Pablo Endres, Richard Feist, Andrea Ghirardini, Julian “HammerJammer” Ho, Marco Ivaldi, Dru Lavigne, Stephane Lo Presti, Christopher Low, Ty Miller, Armand Puccetti & et al.
Sistemas operativos: Un enfoque basado en conceptos de Dhananjay M. Dhamdhere
Pro Git de Scott Chacon y Ben Straub
Expert C Programming: Deep secrets de Peter Van Der Linden.
Podría hablar maravillas de cada uno de estos libros, pero por hoy tomaremos algunos de los pasajes del último en la lista, puesto que muchas de estas anéctodas me han cautivado y ayudado a comprender mejor algunos de los intrincados secretos de C y la programación en general :)
Unix y C
Cuando hablamos de UNIX, la historia se entrelaza con el origen de este sistema y el desarrollo del lenguaje que hasta el día de hoy es uno de los más utilizados en el desarrollo del mismo y sus derivados (incluyendo Linux). Y curiosamente, estos dos nacen de un “error”.
Multrics fue un mega proyecto que juntó a los laboratorios Bell, General Electric y el mismo MIT para crear un sistema operativo, dicho sistema presentó muchos errores, y entre uno de los más importantes, fallos de performance que hacía del sistema algo practicamente inutilizable. Hablamos del año 1969, por lo que el hardware de esa época no podría soportar la cantidad de software que se necesitaba para correr el sistema mismo.
No fue hasta 1970 que un par de ingenieros de Bell empezaron a trabajar en un sistema operativo simple, rápido y ligero para el PDP-7. Todo el sistema había sido escrito en Assembler y había sido llamado UNIX como parodia a Multrics puesto que este solo deseaba hacer pocas cosas, pero hacerlas bien en lugar del tremendo trabajo desperdiciado que significó el segundo. Ahora podrán entender por qué Epoch comienza el 1ro de enero de 1970. :) Un dato bastante curioso para mí. En ese momento todavía no se hablaba de un C propiamente dicho, sino de un New B puesto que las ideas de Ritchie provenían del ya utilizado lenguaje B de esa época.
Early C
Con el paso de los años (1972-3) el término C empezó a ser utilizado puesto que el lenguaje nuevo empezaba a tomar forma, y por esta época nace otro dato curioso, muchos programadores y chistes de programadores dicen:
Los programadores saben que se empieza a contar desde 0 en lugar de 1.
Pues esto no es del todo cierto :) la verdadera razón por la que esto es considerado así hasta el día de hoy es porque en su creación, para los escritores de compiladores era más sencillo calcular un arreglo utilizando offsets, estos indican la distancia que existe desde un punto de origen hasta el objetivo deseado, es por esto que:
array[8]=2;
Nos indica que el elemento 9 de array es definido como 2, porque al array se le suman 8 unidades para llegar al espacio de memoria donde se almacenará el elemento 2. Antes de C, muchos lenguajes empezaban a contar desde 1, gracias a C, ahora casi todos comienzan con 0 :) así que no es culpa de los programadores, sino de los escritores de compiladores que esto sea así.
The Bourne Shell
Este es un tópico que aunque no está directamente relacionado con C, puede ayudar a más de uno a entender por qué la programación en Shell es tan peculiar, y ciertamente es curioso saberlo. Steve Bourne escribió por esa temporada un compilador de Algol-68, este es un lenguaje en el que las llaves ( {} ) son reemplazadas por palabras, por lo que lo podríamos definir de la siguiente manera en C:
#define IF if(
#define THEN ){
#define ELSE }else{
#define FI };
Estos son solo algunos ejemplos de lo que entiende Algol, pero si lo aplicamos a la programación en shell el día de hoy, ya entenderán por qué en shell tus programas requieren de un fi para cada if :) ciertamente interesante.
Comiencen a leer
No puedo contarles todos los detalles del libro, especialmente porque muchos de estos ya son temas de programación que requieren un fondo previo para poder ser comprendidos, pero pensé en compartir con ustedes algunas de las anecdotas curiosas que fui encontrando en el camino :) No he tenido tiempo de trabajar en algunos de los artículos que han estado en la lista de pendientes porque simplemente estos últimos libros me han atrapado y los estoy disfrutando cada día y sobre todo tratando de comprenderlos al máximo. Saludos y ya pronto podré compartir con ustedes más temas, saludos.
Buenas con todos :) Antes de continuar con los textos de la lista de pedidos, quiero celebrar el lanzamiento de git 2.16 agradeciendo a cada uno de los que mandó un parche y a cada uno de los usuarios, en total tuvimos como 4000 líneas entre actualizaciones y correcciones, lo cual no habla muy bien de mi primera versión, pero si de la amabilidad de ustedes :) ¡Gracias! Ahora bien, les contaré un pequeño secreto, hasta ahora no ha habido una vez en la que no me haya sentado a escribir un artículo y haya pensado mucho al respecto, normalmente solo escribo de corrido, y después el buen lagarto se toma la amabilidad de corregir mis faltas de tipeo :) así que gracias a él también.
Esto no es lo mejor cuando hablamos de escribir artículos, supuestamente debería tener un objetivo y armar una estructura, y marcar pequeños puntos y revisiones y etc etc… Ahora bien, esto no solo aplica para los blogs en general, sino que es fundamental en un software que pretende ser bueno :) Para esta tarea, y tras algunos problemas con el software de control de versiones que se usaba en el desarrollo del kernel hace unos años, nació git :)
¿Dónde aprender git?
La cantidad de documentación existente en torno a git es descomunal, incluso si solo tomamos las páginas de manual que vienen con la instalación, tendríamos una cantidad inmensa de lectura. Yo personalmente encuentro el libro de git bastante bien diseñado, incluso yo he traducido algunos de los segmentos de la sección 7, todavía me faltan unos cuantos, pero denme tiempo :P tal vez en este mes pueda traducir lo que queda de esa sección.
¿Qué hace git?
Git está diseñado para ser rápido, eficiente, simple y soportar grandes cargas de información, después de todo, la comunidad del kernel lo creo para su software, el cual es uno de los trabajos conjuntos más grandes del software libre del mundo y cuenta con cientos de contribuciones por hora en una base de código que supera el millón de líneas.
Lo interesante de git es su forma de mantener las versiones de la data. Antiguamente (otros programas de control de versiones) tomaban comprimidos de todos los archivos existentes en un punto de la historia, como hacer un backup. Git tiene un enfoque diferente, al realizar un commit se marca un punto en la historia, ese punto en la historia cuenta con una serie de modificaciones y trabajos, al final del día, se juntan todas las modificaciones a lo largo del tiempo y se obtienen los archivos para poder comprimir o marcar como hitos de versiones. Como sé que todo esto suena complicado, voy a llevarlos por un mágico viaje en un ejemplo super básico.
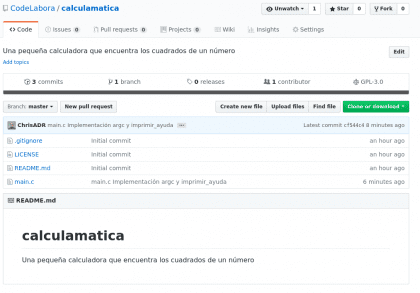
Pequeño proyecto de calculamática
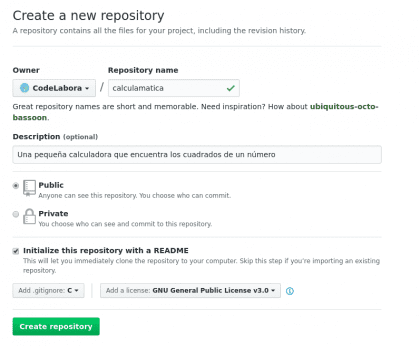
La calculamática será un programa que encontrará los cuadrados de un número dado, lo haremos en C y será lo más simple posible, así que no esperen muchos controles de seguridad de mi parte. Primero vamos a crear un repositorio, lo haré con Github para matar dos pájaros de un tiro:
Diseño propio. Christopher Díaz Riveros
Hemos agregado un par de cosas bastante simples como la licencia (muy importante si quieres proteger tu trabajo, en mi caso, obligarlos a compartir los resultados si lo quieren usar de base :P)
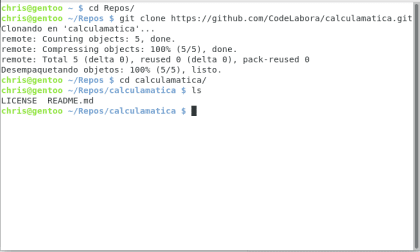
Ahora vamos a ir a nuestra querida terminal, git clone es el comando que se encarga de descargar el repositorio ubicado en la url asignada y crear una copia local en nuestro equipo.
Diseño propio. Christopher Díaz Riveros
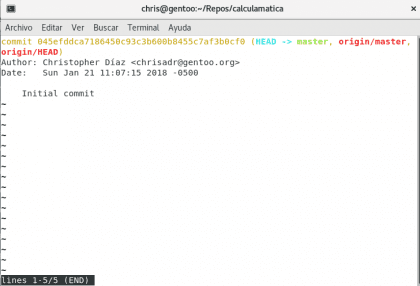
Ahora vamos a revisar con git log lo que ha ocurrido en la historia de nuestro proyecto:
Aquí tenemos mucha información en diversos colores :) vamos a tratar de explicarla:
la primer línea amarilla es el “código de barras del commit” cada commit tiene su propio identificador único, con el cual puedes hacer bastantes cosas, pero lo vamos a dejar para después. Ahora tenemos HEAD de celeste y master de verde. Estos son “punteros” su función es apuntar a la ubicación actual de nuestra historia (HEAD) y la rama en la que estamos trabajando en nuestra computadora (master).
origin/master es la contraparte de internet, origin es el nombre por defecto que se ha asignado a nuestra URL, y master es la rama en la que está trabajando… para hacerlo sencillo, los que tienen un / son aquellos que no se encuentran en nuestro equipo, sino que son referencias a lo que está en internet.
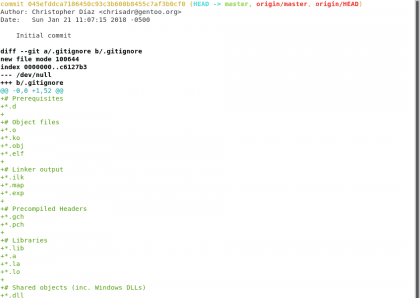
Después tenemos el autor, la fecha y hora y el resumen del commit. Esta es una pequeña reseña de lo que ha sucedido en ese punto de la historia, muy importante en muchos proyectos y ahí se condenza bastante informaicón. Vamos a ver más de cerca lo que sucedió en el commit con el comando git show <código-de-commit>
Diseño propio. Christopher Díaz Riveros
El comando git show nos lleva a esta pantalla en formato parche, donde se aprecia lo que se ha agregado y lo que se ha quitado (si se hubiese quitado algo) en ese momento de la historia, hasta aquí solo nos muestra que se agregaron los archivos .gitignore,README.md y LICENSE.
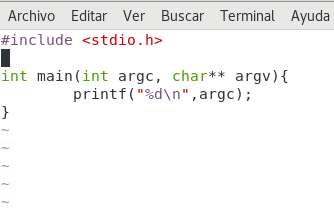
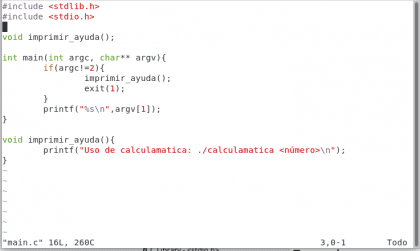
Ahora vamos a lo nuestro, vamos a escribir un archivo :) crearemos el primer hito en nuestra historia :D :
Diseño propio. Christopher Díaz Riveros
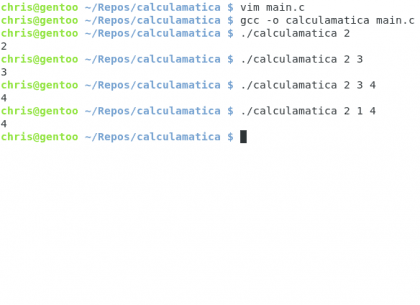
Brevemente, vamos a crear un programa que nos muestre la cantidad de argumentos pasados al momento de ejecutarlo, simple :)
Diseño propio. Christopher Díaz Riveros
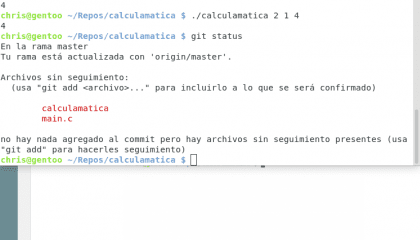
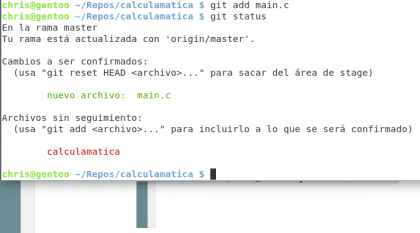
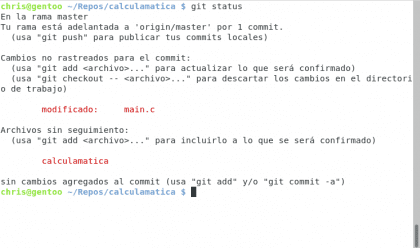
Eso fue fácil :) ahora vamos a ver el siguiente comando útil: git status
Diseño propio. Christopher Díaz Riveros
Algún alma de buen corazón ha traducido git para hacerlo sencillo de seguir, aquí tenemos mucha información útil, sabemos que estamos en la rama master, que estamos actualizados con origin/master(la rama de Github), ¡que tenemos archivos sin seguimiento! y que para agregarlos tenemos que usar git add, vamos a probar :)
Diseño propio. Christopher Díaz Riveros
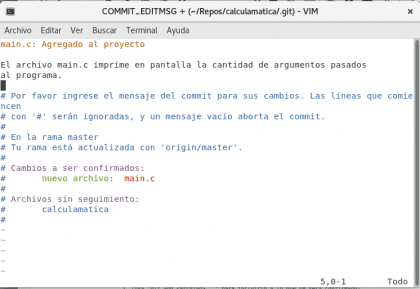
Ahora tenemos un nuevo espacio de verde, en el cual se muestra el archivo que hemos agregado a la zona de trabajo. En este lugar podemos agrupar nuestros cambios para poder realizar un commit, el commit consiste en un hito a lo largo de la historia de nuestro proyecto, vamos a crear el commit :) git commit
Diseño propio. Christopher Díaz Riveros
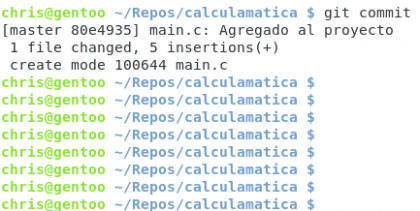
Brevemente explicado, la línea amarilla es el título de nuestro commit, yo escribo main.c por una mera referencia visual. El texto de negro es la explicación de los cambios realizados desde el commit anterior hasta ahora :) guardamos el archivo y veremos nuestro commit guardado en el registro.
Diseño propio. Christopher Díaz Riveros
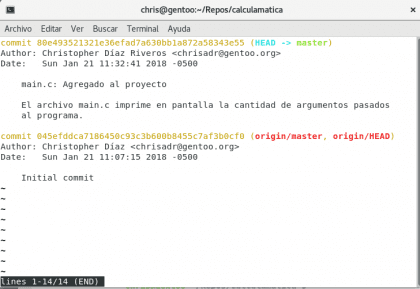
Ahora vamos a ver la historia de nuestro proyecto con git log
Diseño propio. Christopher Díaz Riveros
Nuevamente en el log, ahora podemos ver que la línea verde y la roja han diferido, eso se debe a que en nuestra computadora, estamos un commit por encima de los almacenados en internet :) vamos a seguir el trabajo, supongamos que ahora quiero mostrar un mensaje en caso de que el usuario ponga más de un argumento en el programa (lo cual haría que la calculadora se confunda :) )
Como podemos ver, nuestro programa ha crecido bastante :D , ahora tenemos la función imprimir_ayuda() que muestra un mensaje sobre cómo usar la calculamatica, y en el bloque main() ahora hacemos una revisión con if(algo que veremos en un tutorial de programación en otro momento, por ahora solo es necesario saber que si se ingresan más de 2 argumentos a la calculamática, que el programa termine y se muestre la ayuda. Vamos a ejecutarlo:
Diseño propio. Christopher Díaz Riveros
Como pueden ver ahora imprime el número que ha sido entregado en lugar de la cantidad de argumentos, pero eso yo no se los había contado antes :) para los curiosos echo $? muestra el código de salida del último programa ejecutado, el cual es 1 porque ha terminado en error. Ahora vamos a revisar cómo va nuestra historia:
Diseño propio. Christopher Díaz Riveros
Ahora sabemos que estamos 1 commit delante de Github, que el archivo main.c ha sido modificado, vamos a crear el siguiente commit haciendo git add main.c y luego git commit:)
Diseño propio. Christopher Díaz Riveros
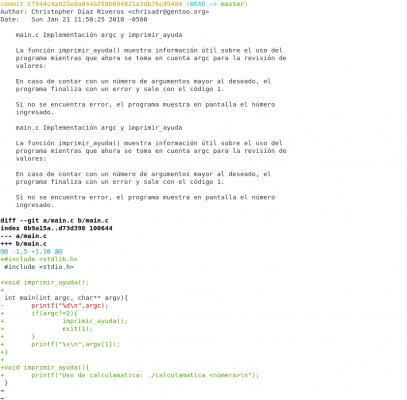
Ahora hemos sido un poco más específicos, puesto que hemos implementado una función y cambiado el código de validación. Ahora que se ha guardado vamos a revisar nuestro último cambio. Podemos verlo con git show HEAD
Diseño propio. Christopher Díaz Riveros
Ahora se pueden apreciar las líneas rojas y verdes, hemos agregado la biblioteca stdlib.h, modificado gran parte del código y agregado la función a nuestra historia.
Ahora vamos a ver el log: (git log)
Diseño propio. Christopher Díaz Riveros
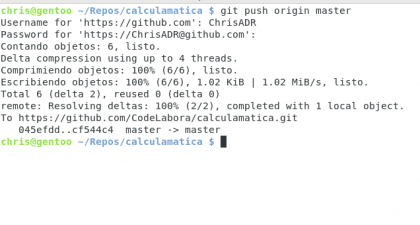
Podemos ver que estamos dos commits adelante de la versión de Github, vamos a igualar un poco el marcador :) para eso usamos git push origin master
Con esto decimos, envía mis commits al url origin en la rama master
Diseño propio. Christopher Díaz Riveros
¡Felicidades! Ahora sus cambios están en Github, ¿no me creen? vamos a revisarlo ;)
Diseño propio. Christopher Díaz Riveros
Ahora tenemos los 3 commits en Github :)
Resumen
Hemos tocado los aspectos más básicos de git, ahora pueden crear un flujo de trabajo simple en sus proyectos, esto no es casi nada de toda la gran variedad de cosas que pueden hacerse con git, pero ciertamente es lo más práctico y de todos los días para un desarrollador o blogger. No hemos llegado al final de la calculadora, pero eso lo vamos a dejar para otro momento ;) Muchas gracias por llegar hasta aquí y espero les ayude a participar en varios proyectos :D Saludos
Hola a todos :) estos días he cumplido con varios logros personales y ciertamente me han dejado pensando un poco, así que quiero compartir con ustedes los resultados de mi divagar, además de responder de manera indirecta a algunos correos que me llegan al buzón cada cierto tiempo :)
Todos tenemos un principio
Esta es una anécdota que ya he contado en mi primer artículo, pero hasta el día de hoy me sigue impactando en esos momentos que me tomo para reflexionar sobre mi camino en el desarrollo de software. Cuando recién tenía Ubuntu en mi laptop, recuerdo un día haber estado en la biblioteca y haber querido actualizar mi computadora, nunca lo había hecho, pero no sé por qué en ese momento lo necesitaba… creo que había algo que quería instalar para un curso y no aparecía en los repositorios cuando se suponía que debía estar… todavía me acuerdo de la frustración que sentí y el desanimo con el que recorría las listas de resultados de google hasta que encontré la solución… me faltaba ejecutar el oscuro y misterioso comando:
sudo apt-get update
Evidentemente en ese tutorial seguía la línea:
sudo apt-get upgrade
al poco tiempo y leyendo en otros lugares había incluso visto :
sudo apt-get update && sudo apt-get upgrade
pero recuerdo curiosamente haber escrito:
sudo apt-get update && upgrade
pensando que de esa manera se ejecutaría lo mismo :) qué tiempos aquellos…
Todos tenemos más de un principio
Ahora en inevitable que llegue a mi mente el primer momento en que escuché de Kali Linux, ciertamente estaba maravillado por esto de la seguridad, había leído un post que trataba sobre descifrado de claves de redes inhalámbricas, me sentía todo un hacker al momento de ejecutar john.
Horas pasaron en el primer intento por descubrir la clave de una red WEP que se encontraba en las cercanías de mi tarteja de wifi… me llevó un buen tiempo descubrir que las listas de claves por defecto de john solo tenían palabras en inglés, algo que ciertamente no es muy útil en mi ciudad, y mucho menos en las cercanías de donde vivo…
Mi primer libro de ‘hacker’
Recuerdo con mucho cariño mi primer libro de hacker, ciertamente fue todo un desafío… primero porque en ese momento todavía no estaba acostumbrado a leer en inglés, segundo… y más importante aún, porque cada línea de texto me parecía chino mezclado con algún tipo de lenguaje alienígena. Para todos aquellos que se estén preguntando qué libro es ese… la respuesta está aquí :)
Y fue ese un punto interesante en mi camino de aprendizaje, porque ese fue el momento en que descubrí que no me gustaba usar Kali Linux sin saber qué estaba sucediendo a cada paso, ciertamente es interesante correr cosas como nmap o burp o mil y un herramientas más que vienen por defecto. Descubrí que quería saber por qué funcionaban, y cómo lo hacían. Desde ese momento dejé de practicar con las herramientas de Kali y empecé a leer sobre lenguajes de programación.
Y volvimos al primer instante donde todo parecía chino alienígena :) ciertamente entendía poco o nada de lo que leía, y al mismo tiempo seguía y seguía, devorando información en cada rincón de internet a más no poder… evidentemente me preocupaba por conseguir la mejor fuente posible para llenarme de información.
Entrar en lo profundo
Pasó un poco de tiempo y ya estaba en Gentoo, y me llamaba mucho la curiosidad de muchas cosas, y con el pasar de los días aprendía mucho sobre compilación y sobre construcción, y sobre seguridad, y sobre muchas cosas. Pero evidentemente al principio, como en todas las experiencias previas, sentía que leía chino alienígena.
¿Por qué cuento esto?
Pues porque estos días empecé a mandar mis primeros parches (cosas bastante pequeñas) a la comunidad del kernel, hacía mucho tiempo había escuchado que era una comunidad de comentarios despiadados, que no eran el lugar para un novato en el mundo FOSS, que era muy selectivos con lo que se aplicaba y ¿saben lo que he descubierto? que no es nada de eso, si conoces las reglas :)
Ya en otro momento hablamos sobre el entrar a casa a ajena, y no respetar las reglas de casa… evidentemente me ha tomado tiempo aprender estas reglas, aprender a usar git lo suficientemente bien como para mandar un parche adecuadamente, aprender a usar un software de análisis estático de código, aprender a revisar mis trabajos con detenimiento, aprender a comunicarme con la comunidad, aprender a usar vim, aprender C… y sí, al principio todo puede parecer chino alienígena, pero conforme van pasando los días, todo esto cobra sentido y te das cuenta de cuánto has avanzado y cuánto has aprendido.
Hoy
Hoy conozco más comandos y formas de actualizar un sistema de las que podría haber imaginado, lo mismo que hoy conozco y domino en cierta medida el flujo de trabajo colaborativo en una comunidad… hoy leo aquellas páginas (o incluso algunas más complicadas) y no me pierdo en el camino…
Mañana
Si hablamos de mañana… pues todavía hay mucho que quiero aprender, quiero conocer nuevas tecnologías, quiero dominar nuevos lenguajes, quiero construir nuevas comunidades, quiero enseñar a más personas, y probablemente pasará lo que ha pasado en cada primer paso de mi descubrir tecnológico… que no voy a entender nada al principio :) y a esto quería llegar con tantas palabras, mucho se habla de la zona de confort, yo creo que ese es el lugar a donde llegan todos aquellos que creen que han dominado algo… porque tan solo creer que lo has dominado, es ciertamente motivo y razón suficiente para descubrir que te equivocas, y que todavía te falta mucho por recorrer. Al principio tal vez no entiendas, tal vez te equivoques, tal vez incluso quieras tirar la toalla, pero todo eso es necesario para no llegar jamás a la zona de confort, porque si solo haces lo que conoces, ¿qué más confortable que eso?
Este lo dejo hasta aquí porque solo es una pequeña opinión… no quiero que piensen que sé más de lo que en realidad sé, lo poco que he aprendido es porque me he dado el trabajo de nunca estar en una zona de confort por tiempo suficiente como para creer que “domino” algún tema :) y para los que me preguntan que cuándo estarán listos para colaborar en un proyecto o comunidad, pues la respuesta es sencilla…
Si te sientes listo, ya estás tarde.
Gran parte de la aventura está en descubrir cosas :) si ya todo lo conoces y dominas, todo pierde sentido :) es por esto que disfruto tanto aprendiendo sobre GNU/Linux, porque es un mundo que no parece acabar. Cierto es que puedes dedicarte a hacer la misma labor por muchos días o años sin crecer, pero también es cierto que puedes hacer una labor sin dominarla, pero aprendiendo mucho cada día :) Gracias a los que lleguen hasta aquí, y saludos y cuidado con su zona de confort
Muy buenas con todos, antes de entrar al hardening de tu equipo, quiero contarles que el installador que estoy desarrollando para Gentoo ya está en su fase pre-alpha :D esto quiere decir que el prototipo es lo suficientemente robusto como para poder ser probado por otros usuarios, pero al mismo tiempo todavía falta mucho por recorrer, y el feedback de estas etapas (pre-alpha,alpha,beta) ayudará a definir rasgos importantes sobre el proceso :) Para los interesados…
PS. todavía tengo la versión exclusivamente en inglés, pero espero que para el beta ya tenga su traducción a español también (estoy aprendiendo esto de las traducciones en tiempo de ejecución en python, así que todavía hay mucho por descubrir)
Hardening
Cuando hablamos de hardening, nos referimos a una gran variedad de acciones o procedimientos que dificultan el acceso a un sistema informático, o red de sistemas. Precisamente por eso es que es un tema vasto y lleno de matices y detalles. En este artículo voy a listar algunas de las cosas más importantes o recomendables para tener en cuenta al momento de proteger un sistema, intentaré ir de lo más crítico a lo menos crítico, pero sin ahondar mucho en el tema puesto que cada uno de estos puntos sería motivo de un artículo propio.
Acceso físico
Este es sin dudas el primer y más importante problema de los equipos, puesto que si el atacante cuenta con fácil acceso físico al equipo, ya puede contarse como un equipo perdido. Esto es verdad tanto en grandes centros de data como en laptops dentro de una empresa. Una de las principales medidas de protección para este problema son las claves a nivel de BIOS, para todos aquellos a los que suene nuevo esto, es posible poner una clave al acceso físico de la BIOS, de esta manera si alguien quiere modificar los parámetros de inicio de sesión y arrancar el equipo desde un sistema live, no será trabajo sencillo.
Ahora bien, esto es algo básico y ciertamente funciona si es realmente requerido, yo he estado en varias empresas en las que no importa esto, porque creen que el “guardia” de seguridad de la puerta es más que suficiente para poder evitar el acceso físico. Pero vamos a un punto un poco más avanzado.
LUKS
Supongamos por un segundo que un “atacante” ya ha conseguido acceso físico al equipo, el siguiente paso es cifrar cada disco duro y partición existente. LUKS (Linux Unified Key Setup) es una especificación de cifrado, entre otras cosas LUKS permite cifrar con clave una partición, de esta manera, al iniciar el sistema si no se conoce la clave, la partición no puede ser montada ni leída.
Paranoia
Ciertamente existe gente que necesita un nivel “máximo” de seguridad, y esto lleva a resguardar hasta el aspecto más mínimo del sistema, pues bien, este aspecto llega a su cúspide en el kernel. El kernel de linux es la manera en la que tu software va a interactuar con el hardware, si tu evitas que tu software “vea” al hardware, este no podrá hacer daño al equipo. Para poner un ejemplo, todos conocemos lo “peligrosos” que son los USB con vírus cuando hablamos de Windows, pues ciertamente los usb pueden contener código en linux que podría o no ser perjudicial para un sistema, si hacemos que el kernel solo reconozca el tipo de usb (firmware) que deseamos, cualquier otro tipo de USB simplemente sería obviado por nuestro equipo, algo ciertamente un poco extremo, pero podría servir dependiendo de las circunstancias.
Servicios
Cuando hablamos de servicios, la primera palabra que me viene a la mente es “supervisión”, y esto es algo bastante importante, puesto que una de las primeras cosas que hace un atacante al entrar a un sistema es mantener la conexión. Realizar análisis periódicos de las conexiones entrantes y sobre todo salientes es algo muy importante en un sistema.
Iptables
Ahora bien, todos hemos oído sobre iptables, es una herramienta que permite generar reglas de ingreso y salida de data a nivel de kernel, esto es ciertamente útil, pero también es un arma de doble filo. Muchas personas creen que por tener el “firewall” ya están libres de cualquier tipo de ingreso o salida del sistema, pero nada más alejado de la realidad, esto solo puede servir de efecto placebo en muchos casos. Es conocido que los firewalls funcionan a base de reglas, y estas ciertamente pueden ser evitadas o engañadas para permitir transportar data por puertos y servicios por los cuales las reglas considerarían que es algo “permitido”, solo es cuestión de creatividad :)
Estabilidad vs rolling-release
Ahora este es un punto bastante polémico en muchos lugares o situaciones, pero permítanme explicar mi punto de vista. Como miembro de un equipo de seguridad que vela por muchos de los problemas de la rama estable de nuestra distribución, estoy al tanto de muchas, casi todas las vulnerabilidades existentes en los equipos Gentoo de nuestros usuarios. Ahora bien, distribuciones como Debian, RedHat, SUSE, Ubuntu y muchas otras pasan por lo mismo, y sus tiempos de reacción pueden variar dependiendo de muchas circunstancias.
Vayamos a un ejemplo claro, seguro todos han oído hablar de Meltdown, Spectre y toda una serie de noticias que han volado por internet en estos días, pues bien, la rama más “rolling-release” del kernel ya está parchada, el problema radica en llevar esas correcciones a kernels anteriores, ciertamente el “backporting” es un trabajo pesado y difícil. Ahora bien, después de eso, todavía tienen que ser probados por los desarrolladores de la distribución, y una vez que se han completado las pruebas, recién estará a disposición de los usuarios normales. ¿A qué quiero llegar con esto? A que el modelo rolling-release nos exige conocer más sobre el sistema y formas de rescatarlo si algo falla, pero eso es bueno, porque mantener la pasividad absoluta en el sistema tiene varios efectos negativos tanto para quien lo administra como para los usuarios.
Conoce tu software
Este es un adicional bastante valioso al momento de administrar, cosas tan simples como subscribirse a las noticias del software que utilizas puede ayudar a conocer de antemano los avisos de seguridad, de esta manera se puede generar un plan de reacción y al mismo tiempo ver cuánto tiempo toma para cada distribución resolver los problemas, siempre es mejor se proactivo en estos temas porque más del 70% de los ataques a empresas se llevan a cabo por software no actualizado.
Reflexión
Cuando la gente habla de hardening, muchas veces se cree que un equipo “resguardado” es a prueba de todo, y no hay nada más falso. Como su traducción literal lo indica, hardening implica hacer las cosas más difíciles, NO imposibles… pero muchas veces mucha gente piensa que esto conlleva magia oscura y muchos trucos como los honeypots… esto es un adicional, pero si no se puede con lo más básico como mantener actualizado un software o un lenguaje de programación… no existe necesidad de crear redes fantasma y equipos con contramedidas… lo digo porque he visto varias empresas donde preguntan por versiones de PHP 4 a 5 (evidentemente descontinuadas)… cosas que hoy por hoy son conocidas por tener cientos sino miles de fallas de seguridad, pero si la empresa no puede seguir el ritmo de la tecnología, pues de nada sirve que hagan lo demás.
Además, si todos estamos usando software libre o abierto, el tiempo de reacción para los errores de seguridad suele ser bastante corto, el problema viene cuando estamos tratando con software privativo, pero eso lo dejo para otro artículo que sigo esperando poder escribir pronto.
Tristemente he visto que no muchos desean aprender a programar este 2018 :( pero aunque solo hubiese leído mi artículo anterior una persona y tras un poco de tiempo esta sea capaz de mandar un commit a algún proyecto de software libre, yo me daría por satisfecho con mi labor :)
Para los amantes de la seguridad, les prometo que el siguiente será un post sobre seguridad :) así todos contentos, si alguno desea aprender otra cosa (como git, administración de servidores, o yo que sé :p ), o que comente algún otro tema que no pueda responderse de manera sencilla en el cuadro de comentarios, avísenme y vemos cómo podemos trabajarlo ;)
Bueno, ahora si vamos a lo nuestro, anteriormente hablamos sobre tipado, y que este tenía que ver con la forma en la que guardamos nuestras variables en un programa, ahora vamos a revisar un poco de qué ocurre en el interior y esperemos que pueda ser lo suficientemente claro.
Bits
Creo que este es un tema que siempre toco cuando escribo sobre programación, ciertamente es algo que me fascina y que me ha ayudado a comprender muchas cosas, ahora intentaré explicar un poco cómo son, cómo se leen, y para qué sirven :)
Piensen en un interuptor de luz, cuando el circuito está cerrado, tenemos un 0 en la pantalla, cuando cambiamos de posición el interruptor, pues un 1:) ¿sencillo no es cierto?
Ahora, un 0 y un 1 pueden significar muchas cosas, todo depende de la creatividad con que lo tomes, supongamos que yo quiero saber si alguien va a ir al Norte o al Sur, 1 puede significar norte y 0, sur :) digamos que yo quiero saber si alguien es hombre o mujer, 1 puede ser hombre y 0, mujer :) . Ahora quiero saber si esta persona es jóven o mayor (>22), 0 puede significar jóven y 1, mayor. Sigamos imaginando… ¿Tiene alguna mascota? 1 diría que sí, mientras que 0 diría que no. Ahora quiero que lean conmigo la siguiente línea:
1001
Esto es la forma breve de decir…
Una jóven mujer de no más de 22 años se dirige al norte acompañada de su mascota.
lo que es muy diferente a:
0110 o Un hombre con más de 22 años de edad se dirige solo hacia el sur.
Bytes
Ahora vamos a ir un paso adelante, vamos a aprender a leer bytes. Un byte es la sucesión de 8 bits, los cuales se leen de derecha a izquierda y cada 1 representa una potencia de 2 elevado a la n donde n es la posición del bit. Como suena a chino, vamos a poner un pequeño ejemplo :)
01001011 Tenemos este byte, ahora vamos a ir de derecha a izquierda ( <- ) yo voy a ponerlos de arriba a abajo para poder escribir su signifiacdo:
1: el bit al estar en la posición 0 nos indica que tenemos lo siguiente 2 elevado a la cero o 2^0. Esto bien sabemos que equivale a 1.
1: el segundo bit, ahora la posición 1: 2^1 que es lo mismo que decir 2
0: tercer bit… aquí debería ser 2^2, mas como no está encendido, vamos a dejarlo en 0
1:cuarto bit, 2^3 u 8 :)
0: lo mismo que 0
0: otro 0
1:ahora estamos en 2^6 o 64
y finalmente 0 , que ya sabemos lo que significa :) ahora vamos a sumar nuestros resultados y compararlos con la siguiente tabla :) Tenemos un 75 por lo que vamos a buscarlo en la columna Decimal y veremos lo que aparece en Char
¡¡Tenemos una K!! Felicidades, ya saben leer en binario :) Pero los más sagaces habrán podido notar que también hemos obtenido un número decimal, y que este tiene un límite (cuando todos los valores son 1) Ese límite se encuentra en el número 255.
Word
Ahora más de uno me dirá, pero ¿qué pasa si necesito un número mayor a 255? o ¿dónde puedo encontrar otros caractéres como los japoneces? Pues la respuesta es simple, juntemos 2 bytes. Ahora que tenemos dos, la cantidad posible de combinaciones que tenemos es 2^16 o 65536 posibles resultados, como el 0 es uno de esos, el máximo posible es 65535. ¿A alguno le suena ese número? ¿Recuerdan la cantidad máxima de puertos en un sistema linux? Se los dejo de tarea ;)
Double word & quad word
Para los más matemáticos también existen formatos específicos, los double word contienen, como muchos ya habrán imaginado 2 word o 4 bytes (o 32 bits) de información, lo mismo que decir:
11111111111111111111111111111111 o de 0 a 4 294 967 295
A estas alturas muchos se preguntarán qué sucede con los números negativos, es decir, en algún lugar deben estar contemplados ¿no es cierto? Para poder almacenar un número negativo, los desarrolladores de procesadores eligieron ocupar el primer bit de la izquierda como un valor de signo. Esto quiere decir que si el primero bit es 0 hablamos de un número positivo, pero si es 1 tenemos un negativo. Ahora ven por qué los bits son tan especiales, pueden ser lo que tu quieras :D
¡Pero esto evidentemente nos deja con una posición menos para realizar la multiplicación! Por lo que nuestro0 a 4 294 967 295 se convierte en:
-2,147,483,648 a +2,147,483,647
Ahora bien, muchos ya tenemos procesadores de 64 bits, y este es el valor de un quad word, podemos tener valores que van desde el 0 a 18 446 744 073 709 551 615. Ese sí es un número grande :)
¿Por qué 8 bits?
Esto es algo que ya más de uno se estará preguntando, y la respuesta está en el hardware. Desde su origen, los procesadores necesitaban data para poder realizar operaciones. La data se almacena en la memoria de la computadora y cada vez que el procesador la requiere utiliza los buses de data para conseguirla. En la antigüedad, estos buses podían comunicar un máximo de 8 bits por ciclo, esto quiere decir que el máximo y más eficiente modo de mover data, era agrupando 8 bits y mandando estos al procesador.
Con el paso del tiempo, hasta el día de hoy, los procesadores han desarrollado la hablidad de mover 16 bits, 32bits y… 64 bits.
¿Qué tiene que ver con el tipado?
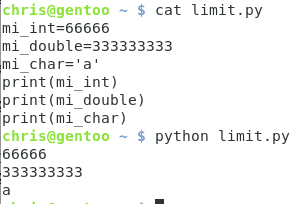
Ya llegamos a la parte donde todo cobra sentido :) El tipado es una propiedad que utilizan los lenguajes de programación para denominar estos espacios de memoria. Todas las variables tienen su contraparte en alguno de estos tipos de data, sin importar cómo sean llamadas. Estos se conocen como tipos de dato primitivos, cada lenguaje fuertemente tipado tiene su concepción de estos valores, y la cantidad que representan. Por ejemplo en C tenemos la biblioteca limits.h que nos muestra la cantidad máxima y mínima de los valores primitivos.
Veamos lo que sucede si intentamos romper uno de los valores:
Diseño propio. Christopher Díaz Riveros
A la derecha tenemos los valores del archivo limits.h y a la izquierda hemos tomado uno de estos valores (unsigned short int) y le hemos asignado un número mayor al correspondiente. Como resultado el compilador nos advierte que estamos utilizando mal la memoria porque la forma binaria de 66666 no puede caber en la forma binaria de 65535. Esto nos lleva a una lección de performance cuando programamos, si tu valor no va a crecer mucho a lo largo del tiempo, o si no requieres valores tan grandes como los de un double o quad word, utilizar el tipo correcto reduce la cantidad de memoria solicitada por el CPU, lo que implica una mayor velocidad de obtención de data si está bien calculada.
En el lado de los intérpretes esto es más sencillo debido a las conversiones implícitas. Cuando definimos una variable en lenguajes como javascript o Python, el intérprete se encarga de entender qué tipo es, y asignar el espacio suficiente de memoria para realizar las operaciones. Veamos un ejemplo sencillo :)
Diseño propio. Christopher Díaz Riveros
Como pueden ver, no tenemos que explicar al intérprete de python el tipo de nuestra variable, porque él mismo se encarga de asignar un tipo y almacenarlo en memoria :)
Conoce tus variables
Esto depende del lenguaje y tipo de implementación que vayas a utilizar, pero el primer paso para poder programar es aprender las variables que puedes utilizar :) Una vez comprendas las variables, estarás en situación de poder utilizarlas de manera eficiente y lógica para almacenar información (provista por un usuario o por el sistema). Este es el primer paso en la escalera de la programación y con suerte, tras leer este artículo, habrás comprendido un poco mejor cómo es que funciona tu computadora y cómo almacena la información. Conmigo será hasta el siguiente artículo, recuerden dejar sus comentarios para saber si hay que reforzar o comentar algún punto en específico. Saludos
Ciertamente esta es una de las preguntas que más llega a mi bandeja de entrada al momento de hablar de programación. Si vamos a comenzar una serie de artículos que les permitan aprender a programar y devolver el conocimiento gratuito en forma de contribuciones a comunidades de software libre/open source en el mundo, es necesario responder a esta básica aunque un poco difícil pregunta. ¿Qué lenguaje de programación debo aprender?
Un poco de historia
Para poder empezar a comprender y elegir un lenguaje de programación, primero debemos conocer un poco sobre la historia de los mismos, sus usos y funciones, y cómo resuelven distintas necesidades a lo largo del tiempo.
Lenguajes de máquina (bajo nivel)
Conocidos comunmente como Assembly, son lenguajes de programación que podríamos definir como dialectos de un idioma más general… Esto suena un poco complicado pero lo voy a ejemplificar… Sabemos que el lenguaje universal de la computación es la electricidad, esto quiere decir que en última instancia lo que una computadora lee son 0s y 1s, vamos a denominar esto como español de computadora. En este ejemplo, el español es la regla básica, pero como bien sabemos, no es lo mismo el español que hablan los latinos al hablado en España, e incluso así, no es lo mismo el español de Perú con el español de Argentina. Evidentemente todos tenemos casi las mismas palabras (0s y 1s), mas el uso y significado pueden variar de acuerdo al contexto.
Esto sucede a nivel de procesador. Cuando hablamos de arquitecturas de computación, (amd64, intel, arm,…) nos referimos al dialecto de ese español de computadora. Esto se debe a que diversas empresas entienden el orden y significado a su manera, por lo que algunos varian en detalles como el flujo de la corriente, o el orden con el que se van a guardar los 0s y 1s.
Estos lenguajes de programación son sumamente veloces, puesto que trabajan al nivel más bajo posible de programación, pero son sumamente dependientes de la arquitectura y ciertamente son un poco más complicados de aprender que el resto. Estos suelen requerir de una base más amplia de conceptos para poder transformar la data y poder ejecutar cosas útiles en ellas. Para los amantes de los videojuegos, un ejemplo serían las consolas SEGA, las cuales utilizaban Assembly para programar sus juegos. Evidentemente en esa época la cantidad de memoria era mínima comparada con hoy, y era necesario dominar un lenguaje que pudiera ser veloz y producir programas ligeros.
Lenguajes de alto nivel
Este gran grupo contempla aquellos lenguajes que vinieron después de Assembly. La necesidad de obtener codigo portable hizo que surgiera un grupo de lenguajes denominados compilados. Entre estos el primero en tomar ventaja fue C, el cual ha tenido predominancia en la programación a nivel de sistema operativo desde los 70s.
Lenguajes compilados
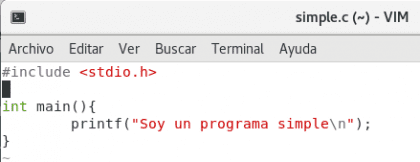
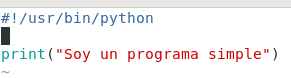
Vamos a ver un ejemplo práctico de lo que comento. Veamos un programa muy simple en lenguaje C que imprime una línea de código.
Diseño propio. Christopher Díaz Riveros
Tras compilarlo tenemos lo siguiente:
Diseño propio.Christopher Díaz Riveros
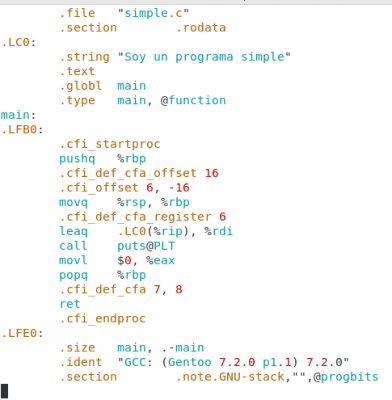
Pero ahora veamos lo que tendríamos que escribir para replicar el mismo resultado en código Assembly:
Diseño propio. Christopher Díaz Riveros
Esta es la traducción de nuestras 3 líneas de código de simple.c, el archivo simple.s es creado mediante el comando gcc -S simple.c y es lo que entendería nuestro procesador en un dialecto Assembly. Evidentemente para poder crear un ejecutable que conste de 0s y 1s es necesario procesar el archivo simple.s y conectarlo con las bibliotecas compartidas de nuestro sistema. Esto se hace mediante un ensamblador (as)y un conector (ld).
Los lenguajes compilados brindan una gran ventaja sobre los de bajo nivel, son portables. La portabilidad entrega código que puede ser ejecutado en distintos procesadores sin la necesidad de generar código específico para cada arquitectura. Otra ventaja evidente es la simplicidad que emplea al momento de leer y escribir código. Dentro de sus principales desventajas tenemos una elevada complejidad, puesto que comparado con el siguiente tipo de lenguajes que veremos, la libertad que brinda C puede ser perjudicial si no se sabe controlar, ciertamente es como entregar una pistola, podría suceder que en la falta de experiencia una persona termine disparando a su propio pie en el intento de limpiar el arma.
Lenguajes interpretados
Dentro de este grupo tenemos una gran variedad de lenguajes, entre los más importantes contamos Python, Ruby, Javascript, PHP, etc… La idea básica de estos lenguajes es brindar una forma rápida de creación y ejecución de programas, esto se debe a que muchos de los procesos difíciles son llevados a cabo en el intérprete, y la programación de la lógica es la que se implementa en el código. Veamos el mismo ejemplo anterior pero esta vez escrito en Python:
Diseño propio. Christopher Díaz Riveros
Dentro de las cosas más resaltantes podemos ver que la primer línea se encarga de llamar al intérprete ( el programa que va a ejecutar nuestra aplicación) y el subsiguiente código es más “simple” que su versión en C, puesto que todo el trabajo pesado se realiza en el intérprete.
Diseño propio. Christopher Díaz Riveros
Los lenguajes interpretados brindan al desarrollador una capa de seguridad mayor, puesto cuentan con controles de seguridad más rigurosos (OJO que no son perfectas, puesto que hasta los mejores pueden cometer errores) y ya no sufrimos el riesgo de disparar un arma sin darnos cuenta, puesto que al primer intento, el intérprete soltaría una alerta y se cancelaría la ejecución. La principal desventaja se hace evidente al momento de ejecutar el programa, puesto que este es más lento que su contraparte binaria, esto precisamente debido a la mayor cantidad de procesamiento para poder asegurar que el código funciona. Si el programa no requiere de plazos extremadamente cortos, la diferencia puede pasar desapercibida, pero si hablamos de miles o millones de datos por segundo, la diferencia se hace exponencialmente notable en los lenguajes compilados.
Tipado
Esta es una caracteríscia de los lenguajes de programación, estos pueden ser fuertemente o débilmente tipados. Este tema lo voy a dejar para otro post, puesto que es necesario y curioso entender cómo se almacena la memoria en un programa, pero por ahora solo necesitamos hacer la distincion: Los lenguajes fuertemente tipados son aquellos que requieren conocer el tipo de dato que va a trabajarse en una variable o constante, mientras que los débilmente tipados pueden realizar conversiones de manera implícita y todo dependerá de una jerarquía de conversión seguida por el lenguaje. (si no se entiende ahora, no hay problema, lo dejaremos para después)
Paradigmas
Al igual que todo en el mundo GNU/Linux, los lenguajes de programación se basan de acuerdo a paradigmas, y se generan comunidades en torno a estos. Por ejemplo tenemos la Fundación Python o Ruby o PHP o Bash (en cuyo caso es la comunidad GNU). A lo que quiero llegar con esto es que no puedo expresar la gran cantidad de pros y contras que tiene cada uno, pero si puedo decirles que donde existe un lenguaje de programación libre, existe una comunidad donde aprender y participar. Vale la pena mencionar que muchos si es que no son todos los intérpretes de lenguajes están escritos en C, o algún derivado cercano, y el desarrollo de los mismos suele llevarse a cabo por un grupo más reducido de la comunidad, quienes se encargan de tomar decisiones que afectarán a todos los usuarios del lenguaje. Pueden incluso formarse instituciones que velen por el desarrollo correcto del lenguaje, como es el caso de C.
¿Cuál elegir?
Ya hemos hablado bastante sobre los lenguajes y todavía no respondo a lo más importante :P . Pero espero que tras haber revisado este pequeño artículo no sea necesario que sea yo mismo quien te diga qué lenguaje elegir, puesto que con esta información estás en toda la capacidad de buscar uno que te genere curiosidad. Evidentemente si deseas aprender a programar en un lenguaje Assembly requerirás de bastante tiempo antes de poder tener algo funcional, el tiempo se reducirá bastante si optas por un lenguaje compilado, donde además de contar con la portabilidad en sistemas *NIX, podrás aprender información referente a el funcionamiento del mismo sistema, puesto que estar en contacto con C o derivados te hace de una manera u otra aprender cómo funciona de manera general un sistema operativo. Por último, si lo que quieres es aprender algo ligero y que te permita hacer mucho sin la necesidad de comprender mucho, los lenguajes interpretados son una manera entretenida de aprender y desarrollar habilidades de programación.
Aprende con algo emocionante
Este es el mejor consejo que puedo darles, si quieren aprender algo, es necesario encontrar algo apasionante primero, sino será bastante difícil sobrepasar la curva de aprendizaje típica de todo lenguaje de programación. Supongamos que administran sistemas, en ese caso tal vez sea necesario aprender un lenguaje ideal para scripting (interpretado), dentro de estos contamos con Perl, Python, Bash, etc etc… Tal vez lo tuyo son los juegos, existen muchos proyectos en lenguajes como Javascript, Lua, C++, dependiendo del tipo de juego que desees realizar. Tal vez te gustaría crear una herramienta a nivel de sistema, pues tenemos C, Python, Perl, como verás algunos se repiten, y esto es debido a que muchos lenguajes pueden ser utilizados para muchas tareas, por eso la definición de lenguajes multipropósitos en la mayoría de estos.
Comienza un proyecto
Con esto no me refiero a que crees el siguiente compilador, o incluso el siguiente lenguaje de programación, un proyecto puede ser arreglar un pequeño bug en tu programa favorito, tal vez incluso ayudar a mejorar la documentación. ¿Por qué la documentación? porque no hay mejor forma de aprender cómo funciona el software que leyendo y ayudando a escribir su documentación, porque luego del código fuente, es la mayor fuente de información que se va a encontrar sobre el programa. En otro momento veremos cómo leer el código de un proyecto y entender las funciones y valores que adquieren.
Muchas gracias por haber llegado hasta aquí y como siempre, sus comentarios me ayudan a generar mejor contenido y saber dónde enfocar la atención, Saludos.