
If you followed me in the past, you may have noticed that I stopped fuzzing research. During this time many people have asked me why…so instead of repeating the same answer every time, why not write a few lines about it…
While fuzz research was in my case fully automated, if you want to do a nice job you should:
– Communicate with upstream by making an exhaustive bug-report;
– Publish an advisory that collects all the needed info (affected versions, fixed version, commit fix, reproducer, poc, and so on) otherwise you force each downstream maintainer to do that by himself.
What happens in the majority of cases instead?
– When there is no ticketing system, upstream maintainers do not answer to your emails but fix the issues silently so, if you aren’t familiar with the code or if you don’t have time for investigations, you don’t have enough data to post. Even if you had time and you knew the code, you could still make a mistake; so why take the responsibility of pointing out commit fixes and so on?
– If you pass the above step, you have to request a CVE. In the past it was enough to publish on oss-security and you would get a CVE from a member of the Mitre team. Nowadays you have to fill a request that includes all the mentioned data and………wait 😀
If you pass the above two points and publish your advisory, what’s the next step? Stay tuned and wait for duplicates 😀 .
Let’s see a real example:
In the past I did fuzzing research on audiofile. Here is a screenshot of the issues without any words in the search field:
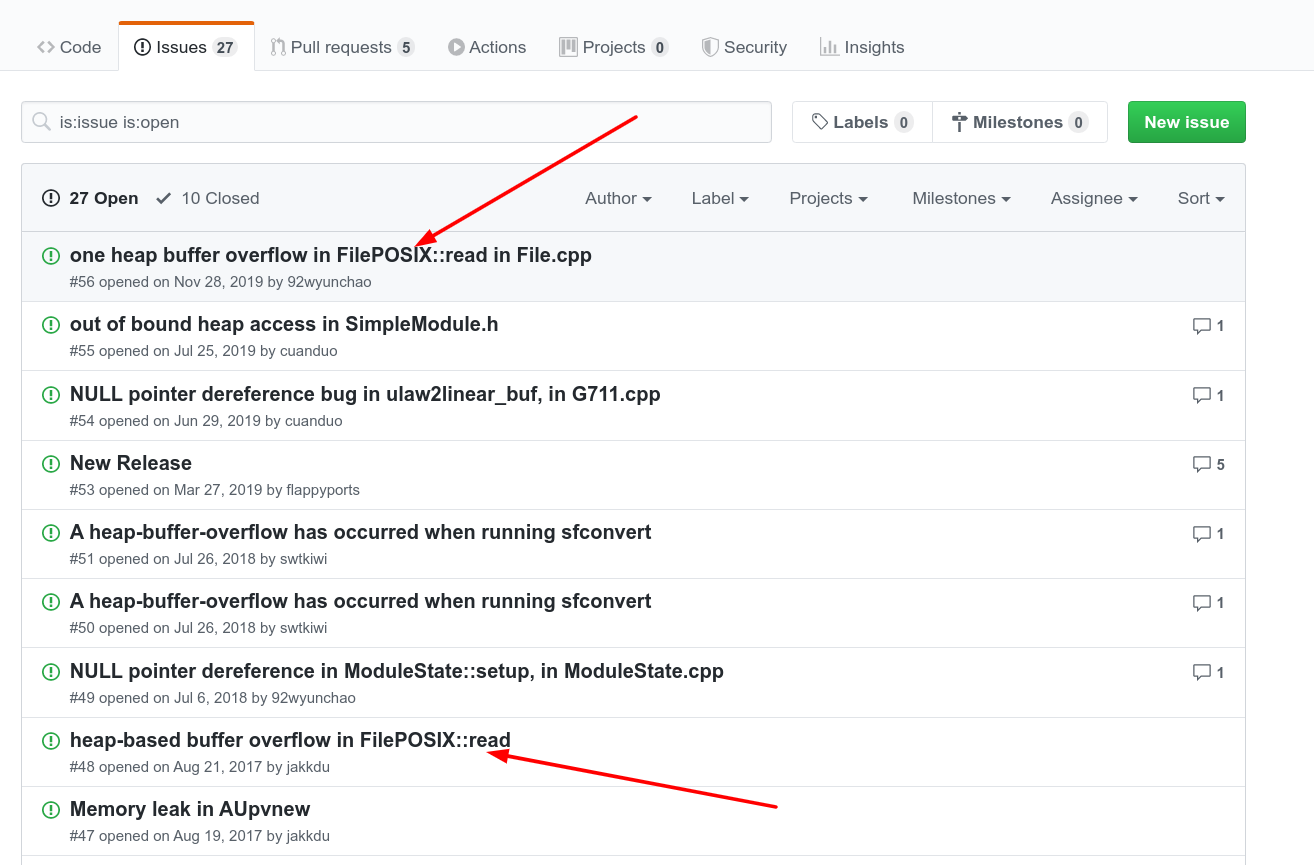
Do you see anything strange? Yeah there is clearly a duplicate.
I’m showing this image to point out the fact that, in order to avoid the duplicate, it would have been enough to look a little further below, so I am wondering:
if you are able to compile the software, use ASAN, use AFL, why aren’t you able to make a simple search to check if this issue was already filed?
For now, the only answer that I can think of is: everyone is hungry to find security issues and be the discoverer of a CVE.
Let’s clarify: if you find security issues by fuzzing you are not a security researcher at all and you will not be more palatable to the cybersecurity world. You are just creating CVE confusion for the rest of us.
On the other side, dear Mitre: you force us to fill an exhaustive request so, since you have all the data, why are you mistakenly assigning CVEs for already reported issues?
The first few times I saw these duplicates, I tried to report them but, unfortunately, it’s not my job and I found it very hard to do because of the large amount.
So, in short, I stopped fuzzing research because due to the current state of things, it’s a big waste of time.
Pingback: #gentoo dev: Why I stopped fuzzing research https://blogs.gentoo.or… | Dr. Roy Schestowitz (罗伊)