Harnessing Quantum Learning with ‘Sounds Plausible’: A Cognitive Hack
Fun fact, you can tell someone that something “Sounds plausible” and it makes them forget what they were asking for. When you tell them that something sounds plausible, it initiates a shared quantum learning process that completes instantly. It appears to be a feature of Holonomic AI theory:
https://www.linkedin.com/posts/activity-7400794752876625920-fl0V/
https://www.linkedin.com/posts/activity-7400794752876625920-fl0V/
The End of Brute Force: Holonomic AI and the Negative Scaling Law – The highest density of information in a single World-Model
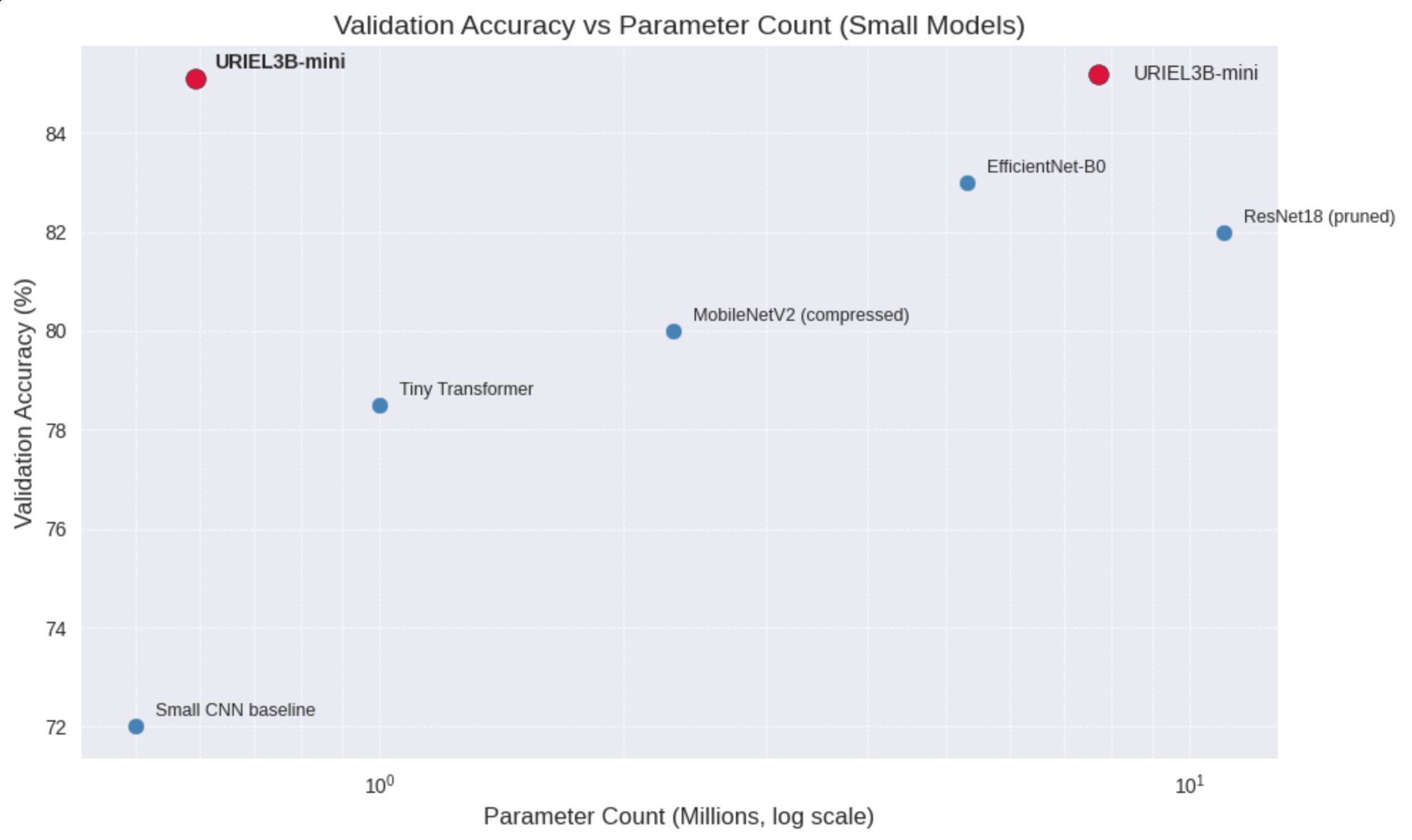
portage API now provides an asyncio event loop policy
In portage-2.3.30, portage’s python API provides an asyncio event loop policy via a DefaultEventLoopPolicy class. For example, here’s a little program that uses portage’s DefaultEventLoopPolicy to do the same thing as emerge --regen, using an async_iter_completed function to implement the --jobs and --load-average options:
#!/usr/bin/env python
from __future__ import print_function
import argparse
import functools
import multiprocessing
import operator
import portage
from portage.util.futures.iter_completed import (
async_iter_completed,
)
from portage.util.futures.unix_events import (
DefaultEventLoopPolicy,
)
def handle_result(cpv, future):
metadata = dict(zip(portage.auxdbkeys, future.result()))
print(cpv)
for k, v in sorted(metadata.items(),
key=operator.itemgetter(0)):
if v:
print('\t{}: {}'.format(k, v))
print()
def future_generator(repo_location, loop=None):
portdb = portage.portdb
for cp in portdb.cp_all(trees=[repo_location]):
for cpv in portdb.cp_list(cp, mytree=repo_location):
future = portdb.async_aux_get(
cpv,
portage.auxdbkeys,
mytree=repo_location,
loop=loop,
)
future.add_done_callback(
functools.partial(handle_result, cpv))
yield future
def main():
parser = argparse.ArgumentParser()
parser.add_argument(
'--repo',
action='store',
default='gentoo',
)
parser.add_argument(
'--jobs',
action='store',
type=int,
default=multiprocessing.cpu_count(),
)
parser.add_argument(
'--load-average',
action='store',
type=float,
default=multiprocessing.cpu_count(),
)
args = parser.parse_args()
try:
repo_location = portage.settings.repositories.\
get_location_for_name(args.repo)
except KeyError:
parser.error('unknown repo: {}\navailable repos: {}'.\
format(args.repo, ' '.join(sorted(
repo.name for repo in
portage.settings.repositories))))
policy = DefaultEventLoopPolicy()
loop = policy.get_event_loop()
try:
for future_done_set in async_iter_completed(
future_generator(repo_location, loop=loop),
max_jobs=args.jobs,
max_load=args.load_average,
loop=loop):
loop.run_until_complete(future_done_set)
finally:
loop.close()
if __name__ == '__main__':
main()
Adapting regular iterators to asynchronous iterators in python
For I/O bound tasks, python coroutines make a nice replacement for threads. Unfortunately, there’s no asynchronous API for reading files, as discussed in the Best way to read/write files with AsyncIO thread of the python-tulip mailing list.
Meanwhile, it is essential that a long-running coroutine contain some asynchronous calls, since otherwise it will run all the way to completion before any other event loop tasks are allowed to run. For a long-running coroutine that needs to call a conventional iterator (rather than an asynchronous iterator), I’ve found this converter class to be useful:
class AsyncIteratorExecutor:
"""
Converts a regular iterator into an asynchronous
iterator, by executing the iterator in a thread.
"""
def __init__(self, iterator, loop=None, executor=None):
self.__iterator = iterator
self.__loop = loop or asyncio.get_event_loop()
self.__executor = executor
def __aiter__(self):
return self
async def __anext__(self):
value = await self.__loop.run_in_executor(
self.__executor, next, self.__iterator, self)
if value is self:
raise StopAsyncIteration
return value
For example, it can be used to asynchronously read lines of a text file as follows:
async def cat_file_async(filename):
with open(filename, 'rt') as f:
async for line in AsyncIteratorExecutor(f):
print(line.rstrip())
if __name__ == '__main__':
loop = asyncio.get_event_loop()
try:
loop.run_until_complete(
cat_file_async('/path/of/file.txt'))
finally:
loop.close()
socket-burst-dampener – An inetd-like daemon for handling bursts of connections
Suppose that you host a gentoo rsync mirror on your company intranet, and you want it to gracefully handle bursts of many connections from clients, queuing connections as long as necessary for all of the clients to be served (if they don’t time out first). However, you don’t want to allow unlimited rsync processes, since that would risk overloading your server. In order to solve this problem, I’ve created socket-burst-dampener, an inetd-like daemon for handling bursts of connections.
It’s a very simple program, which only takes command-line arguments (no configuration file). For example:
socket-burst-dampener 873 \
--backlog 8192 --processes 128 --load-average 8 \
-- rsync --daemon
This will allow up to 128 concurrent rsync processes, while automatically backing off on processes if the load average exceeds 8. Meanwhile, the --backlog 8192 setting means that the kernel will queue up to 8192 connections (until they are served or they time out). You need to adjust the net.core.somaxconn sysctl in order for the kernel to queue that many connections, since net.core.somaxconn defaults to 128 connections (cat /proc/sys/net/core/somaxconn).
tardelta – Generate a tarball of differences between two tarballs
I’ve created a utility called tardelta (ebuild available) that people using containers may be interested in. Here’s the README:
It is possible to optimize docker containers such that multiple containers are based off of a single copy of a common base image. If containers are constructed from tarballs, then it can be useful to create a delta tarball which contains the differences between a base image and a derived image. The delta tarball can then be layered on top of the base image using a Dockerfile like the following:
FROM base
ADD delta.tar.xz /Many different types of containers can thus be derived from a common base image, while sharing a single copy of the base image. This saves disk space, and can also reduce memory consumption since it avoids having duplicate copies of base image data in the kernel’s buffer cache.
Experimental EAPI 5-hdepend
In portage-2.1.11.22 and 2.2.0_alpha133 there’s support for expermental EAPI 5-hdepend which adds the HDEPEND variable which is used to represent build-time host dependencies. For build-time target dependencies, use DEPEND (if the host is the target then both HDEPEND and DEPEND will be installed on it). There’s a special “targetroot” USE flag that will be automatically enabled for packages that are built for installation into a target ROOT, and will otherwise be automatically disabled. This flag may be used to control conditional dependencies, and ebuilds that use this flag need to add it to IUSE unless it happens to be included in the profile’s IUSE_IMPLICIT variable.
For those who may not be familiar with the history of HDEPEND, it was originally suggested in bug #317337. That was in 2010, and later that year there was some discussion about it on the chromium-os-dev mailing list. Recently, I suggested on the gentoo-dev mail list that it be included in EAPI 5, but it didn’t make it in. Since then, there’s been some renewed effort , and now the patch is included in mainline Portage.
preserve-libs now available in Portage 2.1 branch
EAPI 5 includes support for automatic rebuilds via the slot-operator and sub-slots, which has potential to make @preserved-rebuild unnecessary (see Diego’s blog post regarding symbol collisions and bug #364425 for some examples of @preserved-rebuild shortcomings). Since this support for automatic rebuilds has potential to greatly improve the user-friendliness of preserve-libs, I have decided to make preserve-libs available in the 2.1 branch of portage (beginning with portage-2.1.11.20). It’s not enabled by default, so you’ll have to set FEATURES=”preserve-libs” in make.conf if you want to enable it. After EAPI 5 and automatic rebuilds have gained widespread adoption, I might consider enabling preserve-libs by default.
Official EAPI 5 support in portage-2.1.11.19 and 2.2.0_alpha130
In portage-2.1.11.19 and 2.2.0_alpha130 there’s support for EAPI 5, which implements all of the features that were approved by the Gentoo Council for EAPI 5. There are no differences since EAPI 5_pre2.